LongCat-Video-Avatar 1.5 是美团团队于2026年推出的开源音频驱动视频生成框架。用户只需提供静态图像和音频,即可生成口型同步的动态视频,适用于真实人像和动漫角色,具备高保真画面和长视频生成能力。
微软 AI 团队提出了「爬山机器」框架,并训练了参数达到 1T 的 MoE 模型 MAI-Thinking-1。该模型通过自适应熵控制的强化学习,在无第三方数据的情况下实现了长期稳定的性能增长,并在多个基准测试中取得领先水平。
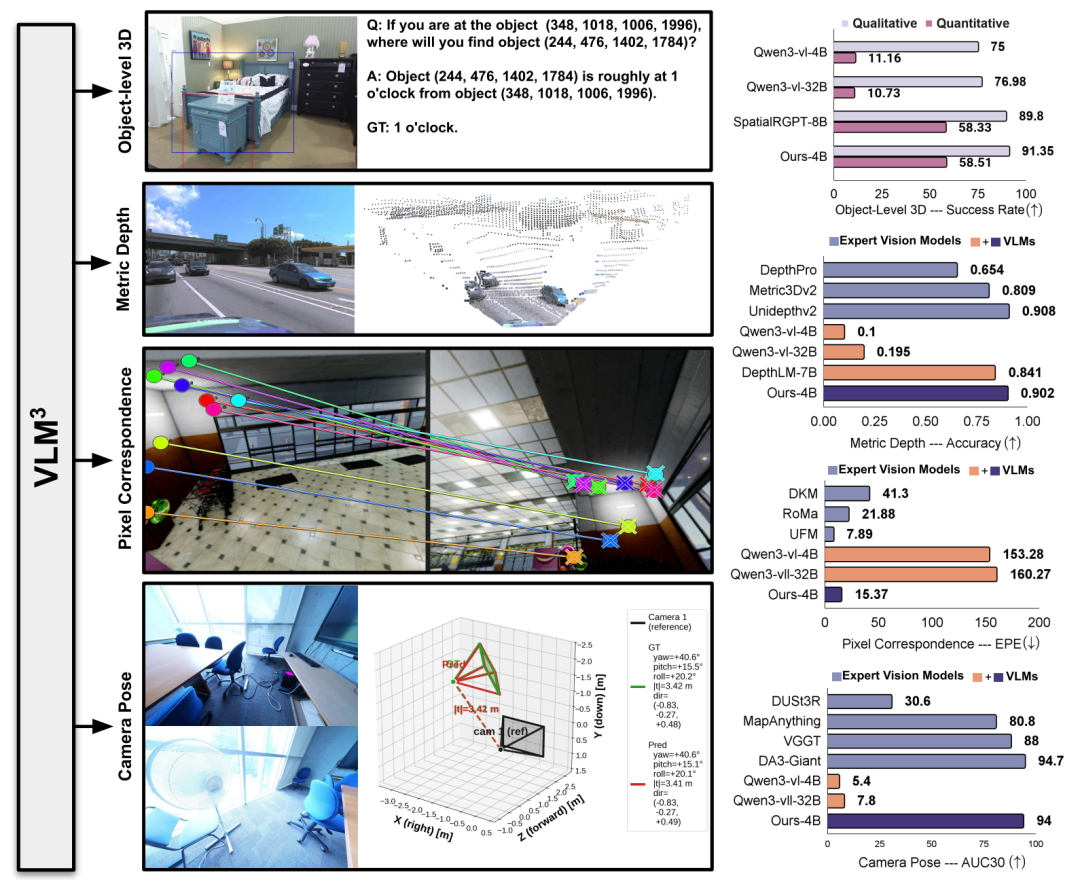
三维空间感知是自动驾驶和机器人领域的核心能力,旨在从二维图像恢复真实世界的空间结构。Meta与普林斯顿大学提出的VLM³框架,基于标准视觉语言模型,统一了物体级三维理解和公制深度估计等任务,显著提升了模型在细粒度三维感知中的表现。研究表明,通用视觉语言模型在三维表征能力上超出预期,为三维视觉领域的统一基础模型提供了新依据。
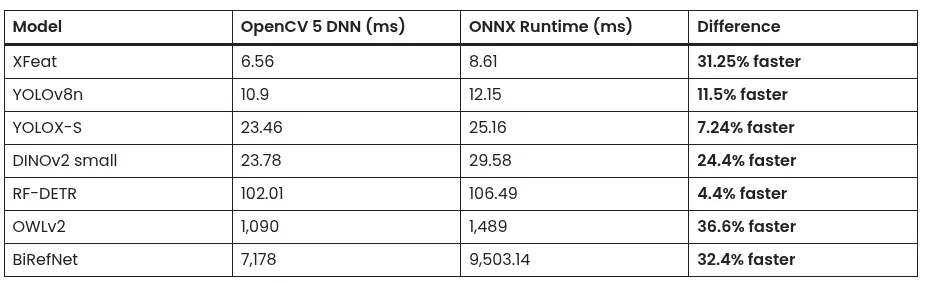
OpenCV 5.0于2026年6月6日发布,新增深度神经网络引擎重写、80% ONNX覆盖率和内置大型语言模型支持等功能,并针对多种硬件进行了优化,计划实现原生GPU支持。
星海图提出的G0.5模型将视觉语言模型与动作生成统一为单一自回归序列,通过共享权重实现推理与动作的耦合,提升机器人控制效率。该模型采用可学习的动作分词器和视觉记忆模块,优化动作生成过程,减少离散化负担,能够在零样本条件下分解任务,直接生成动作,增强对复杂场景的适应能力。
GR00T N1.6和N1.7是NVIDIA开发的视觉语言模型(VLM),用于机器人控制。N1.6改进了模型结构,支持灵活分辨率,并引入新数据集;N1.7在此基础上增强了模型的泛化能力,并在大量人类视频数据上进行预训练,提高了机器人控制的精确性和效率。
本文探讨了觉-语言-动作(VLA)模型在机器人学习中的应用,提出了一种视频生成式价值模型(ViVa),通过预测未来状态来改进价值估计。ViVa结合预训练的视频生成模型、当前观测和本体感知,评估任务进展,提升机器人在复杂环境中的操作能力。研究表明,该方法在真实世界任务中表现优越,能够有效跟踪任务进度并处理新颖物体。
本文介绍了Ψ0模型,该模型结合大规模人类视频数据与真实机器人数据,训练出一种用于类人机器人灵巧运动的视觉-语言动作模型,能够有效提取运动先验,实现复杂的全身控制。
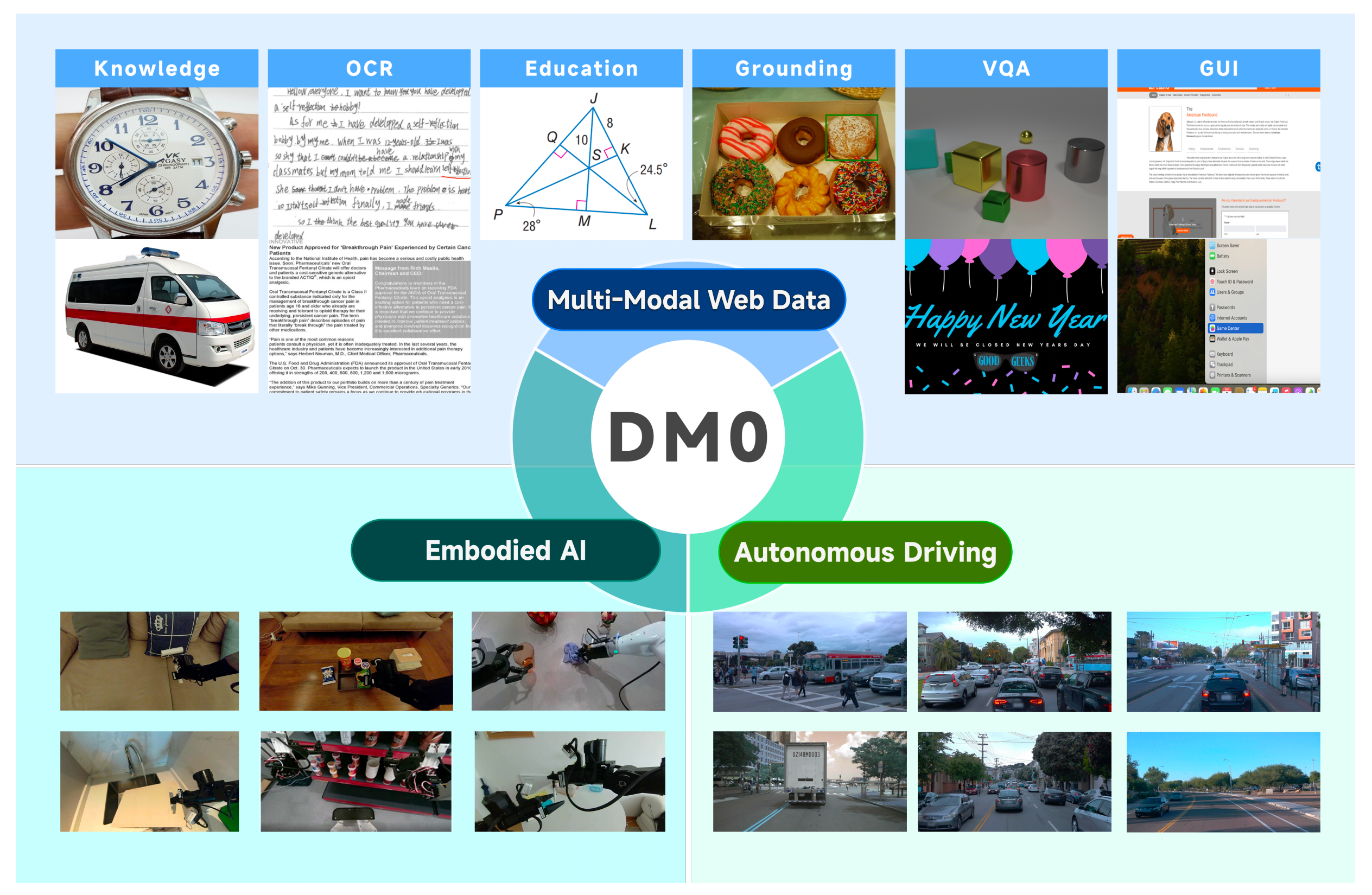
本文介绍了DM0模型,这是一种面向体感智能的视觉-语言-动作(VLA)框架,旨在统一操作与导航。DM0通过多源三阶段训练流程,结合视觉、驾驶和体感数据,克服了传统模型的局限性,并在RoboChallenge基准测试中表现优异,展示了其在物理AI领域的潜力。
本文介绍了一种新型机器人学习模型X-VLA,采用软提示技术以提升跨具身机器人学习的适应性和泛化能力。通过引入可学习的嵌入,X-VLA有效解决了不同硬件和任务环境下的异质性问题,增强了模型在多样化数据集上的表现。该模型在多个基准测试中表现优异,展现出在灵巧操作和适应新领域方面的强大能力。
RDT2是一种新型机器人基础模型,旨在实现跨本体、物体和场景的零样本迁移能力。通过使用UMI数据集和三阶段训练策略,RDT2能够高效处理多样化的真实世界任务,提升机器人在未见物体和场景中的泛化能力。该模型在微调实验中表现优异,尤其在复杂操作和动态任务中,展现出显著的性能提升。
本文介绍了MetaWorld,一个基于分层世界模型的机器人控制框架,旨在弥合高层语义理解与低层物理执行之间的鸿沟。该框架结合视觉-语言模型、模仿学习和强化学习的优势,通过分层架构进行任务解析和动作生成,提升机器人在动态环境中的适应性和泛化能力。
本文介绍了InternVLA-A1模型,该模型结合了多模态大语言模型的语义理解与动态预测能力,旨在提升机器人在复杂环境中的操作能力。通过构建包含真实和仿真数据的多层数据金字塔,InternVLA-A1有效解决了现有模型在场景变化适应性方面的不足,增强了机器人操作的鲁棒性与泛化能力。
本文回顾了作者创业11年的历程,并介绍了上海AI LAB发布的DualVLN模型。该模型结合视觉-语言导航推理与实时控制,采用双系统架构,分别负责高层推理和低层动作执行,提升了动态环境中的导航能力。实验结果表明,DualVLN在多种场景中表现优异,成功率高,导航误差低。
Qwen2.5-32B和Qwen2.5-VL-32B是通义千问系列的两个大模型,分别为纯文本和多模态模型。部署前需确认硬件要求,建议使用Docker环境并安装NVIDIA工具包。模型支持中英文,具备强大推理能力,适用于图文问答和多模态推理。
本文介绍了Hume模型,该模型结合双系统思维(System-1和System-2),提升机器人在复杂任务中的表现。Hume通过价值引导的重复采样和级联动作去噪机制,实现高效的动作预测和实时控制。System-2生成候选动作并评估其价值,System-1则快速执行细化动作,使机器人能够灵活应对动态环境。
文章讨论了人工智能在各领域的应用,强调其在提升效率和决策支持中的重要性。AI技术迅速发展,正在改变我们的工作和生活方式。
jina-vlm是一个具有2.4B参数的视觉语言模型,支持29种语言的视觉问答,性能优越,适合消费级硬件。它结合了SigLIP2视觉编码器和Qwen3语言骨干,在多语言理解和视觉推理方面表现出色,并通过高效的注意力池化连接器减少视觉标记数量,保持多语言能力。
北京人形机器人创新中心于11月13日开源了具身智能VLM模型Pelican-VL 1.0,参数规模为7B和72B,性能超越GPT-5和Google Gemini,成为最强开源多模态大模型。该模型由女性团队主创,采用DPPO训练范式,提升了自我纠错能力,推动机器人在多场景中的应用。
本文介绍了Eagle 2的设计与训练方法,强调数据的多样性和质量。Eagle 2结合视觉编码器与大语言模型,通过动态拼接和多阶段训练策略提升视觉-语言模型性能。
完成下面两步后,将自动完成登录并继续当前操作。