
DM0——面向物理AI的VLA:先VLM上混入物理数据做预训练,之后保持知识隔离的同时训练流匹配动作专家,最后做微调
内容提要
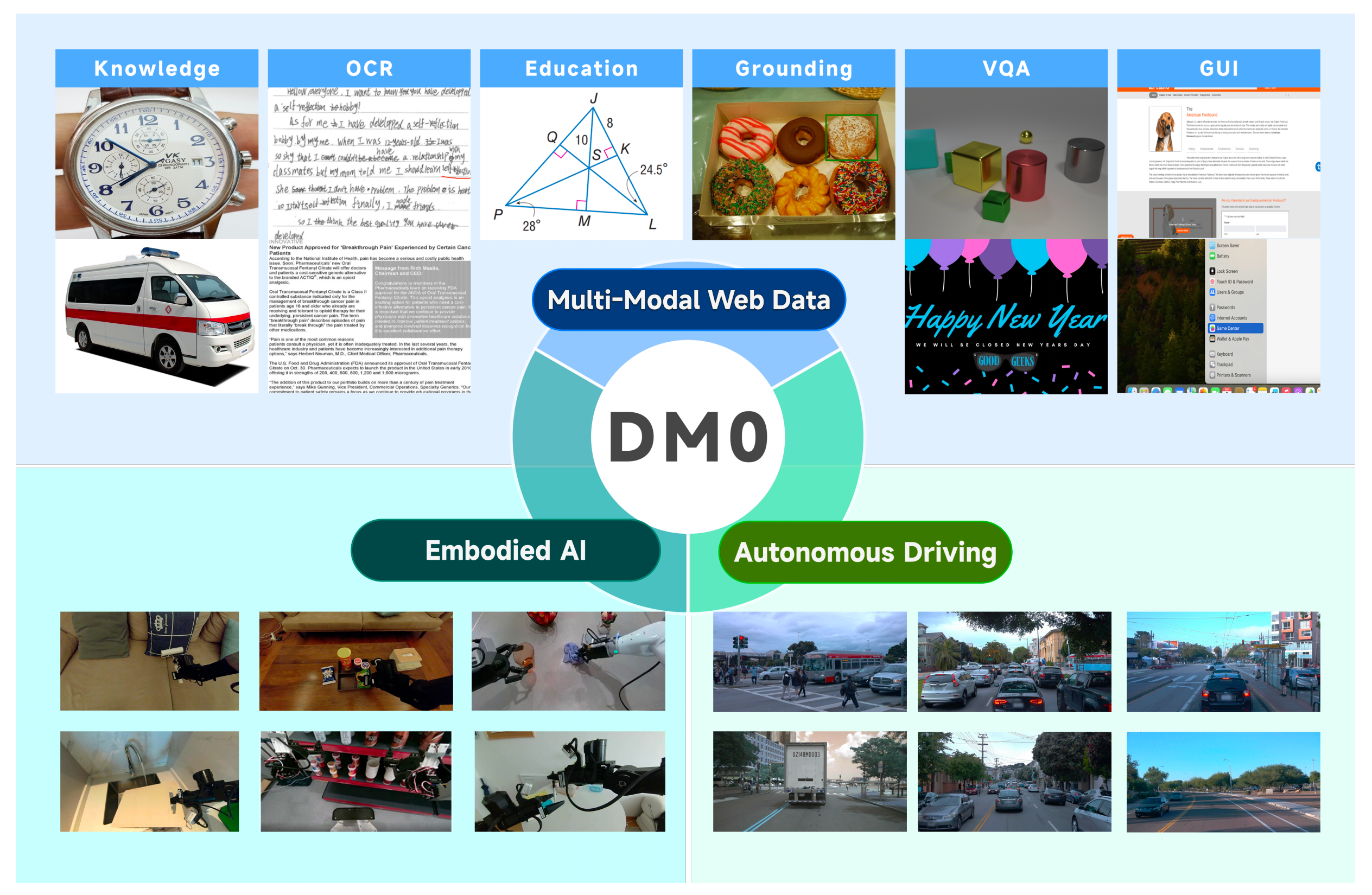
本文介绍了DM0模型,这是一种面向体感智能的视觉-语言-动作(VLA)框架,旨在统一操作与导航。DM0通过多源三阶段训练流程,结合视觉、驾驶和体感数据,克服了传统模型的局限性,并在RoboChallenge基准测试中表现优异,展示了其在物理AI领域的潜力。
关键要点
-
DM0模型是一种面向体感智能的视觉-语言-动作(VLA)框架,旨在统一操作与导航。
-
DM0通过多源三阶段训练流程,包括预训练、中间训练和微调,克服了传统模型的局限性。
-
该框架结合视觉、驾驶和体感数据,确保模型在获得语义知识的同时,也能够学习物理先验。
-
DM0在RoboChallenge基准测试中表现优异,优于现有策略,展示了其在物理AI领域的潜力。
-
模型架构支持在多种任务和数据分布的大规模数据集上进行联合训练,包含视觉-语言模型和动作专家。
延伸解读
DM0模型的创新训练流程
DM0模型采用了多源三阶段训练流程,包括预训练、中间训练和微调。这种方法不仅整合了视觉、语言和动作数据,还确保了模型在学习语义知识的同时,能够掌握物理交互的动态特性。这种创新的训练方式有助于克服传统模型在物理AI应用中的局限性。
知识隔离策略的优势
DM0模型引入了知识隔离策略,以防止在训练过程中,动作专家的梯度影响到预训练的视觉-语言模型。这种策略确保了模型在具身任务中保持其语言和视觉理解能力,同时提升了动作预测的准确性。这一设计对于实现更高效的体感智能至关重要。
RoboChallenge基准测试的表现
DM0在RoboChallenge基准测试中表现优异,超越了多种现有策略。这表明DM0不仅在理论上具有创新性,其实际应用效果也得到了验证。对于研究人员和开发者而言,关注DM0的测试结果可以为未来的物理AI模型设计提供重要参考。
延伸问答
DM0模型的主要目标是什么?
DM0模型旨在统一操作与导航,面向体感智能的视觉-语言-动作(VLA)框架。
DM0模型的训练流程是怎样的?
DM0通过多源三阶段训练流程,包括预训练、中间训练和微调,克服传统模型的局限性。
DM0模型如何结合不同类型的数据?
DM0结合视觉、驾驶和体感数据,确保模型在获得语义知识的同时,也能够学习物理先验。
DM0在RoboChallenge基准测试中的表现如何?
DM0在RoboChallenge基准测试中表现优异,优于现有策略,展示了其在物理AI领域的潜力。
DM0模型的架构包含哪些核心组件?
DM0模型的架构包含基于大语言模型的视觉-语言模型和流匹配的动作专家。
DM0模型如何防止知识的侵蚀?
DM0采用混合梯度策略,将动作专家的梯度与预训练的视觉-语言模型解耦,以防止语义知识的侵蚀。
