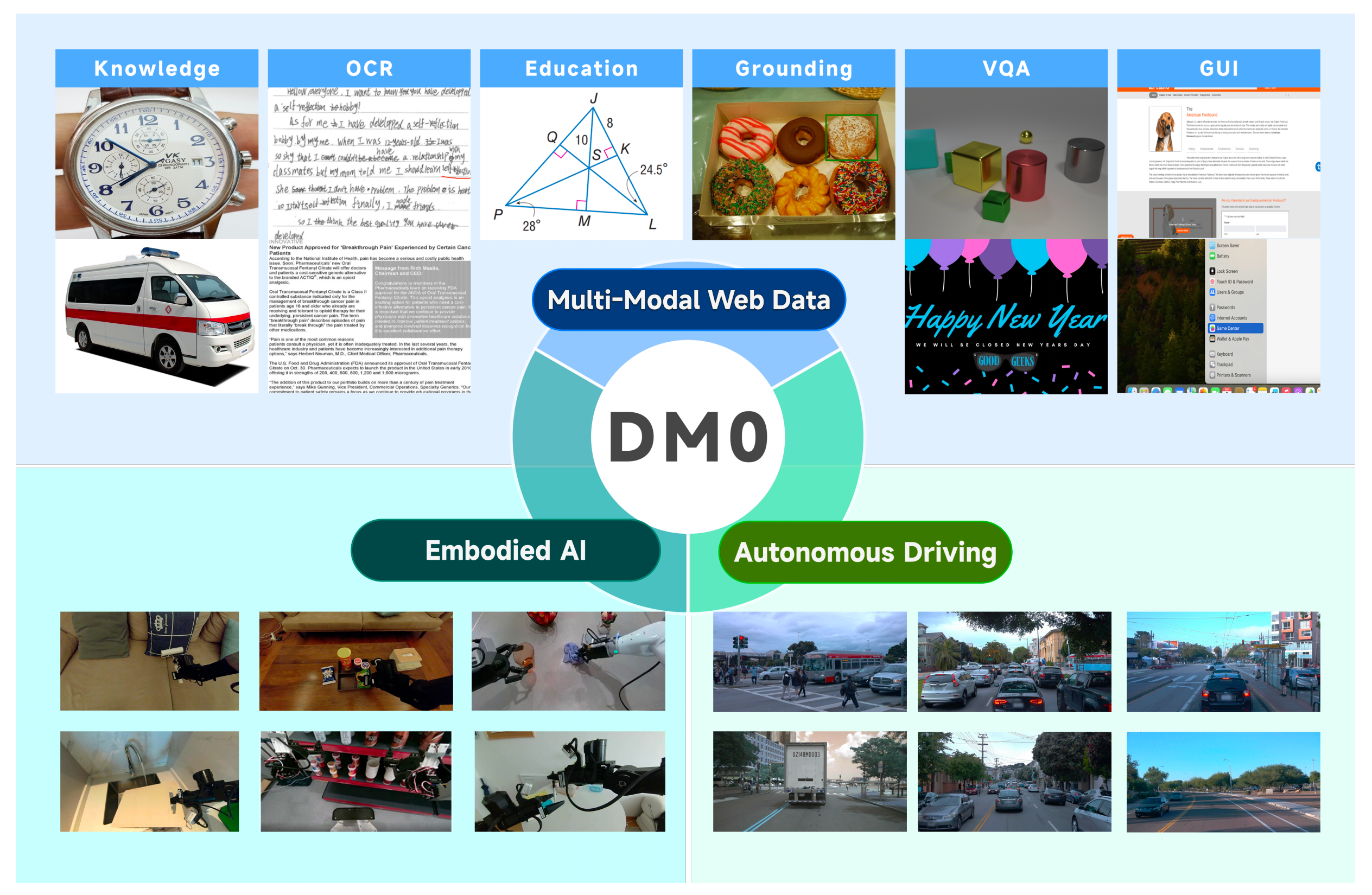
本文介绍了DM0模型,这是一种面向体感智能的视觉-语言-动作(VLA)框架,旨在统一操作与导航。DM0通过多源三阶段训练流程,结合视觉、驾驶和体感数据,克服了传统模型的局限性,并在RoboChallenge基准测试中表现优异,展示了其在物理AI领域的潜力。
完成下面两步后,将自动完成登录并继续当前操作。