在具身智能领域,视觉-语言-动作(VLA)模型面临模仿学习导致的误差累积问题。华为云的HIL-ResRL方法通过人机协同和残差策略,提高了机器人在真实环境中的任务成功率,实验成功率超过95%。该方法无需重训练,适用于多种工业任务,并通过触觉反馈显著提高精度,展示了快速部署的潜力。
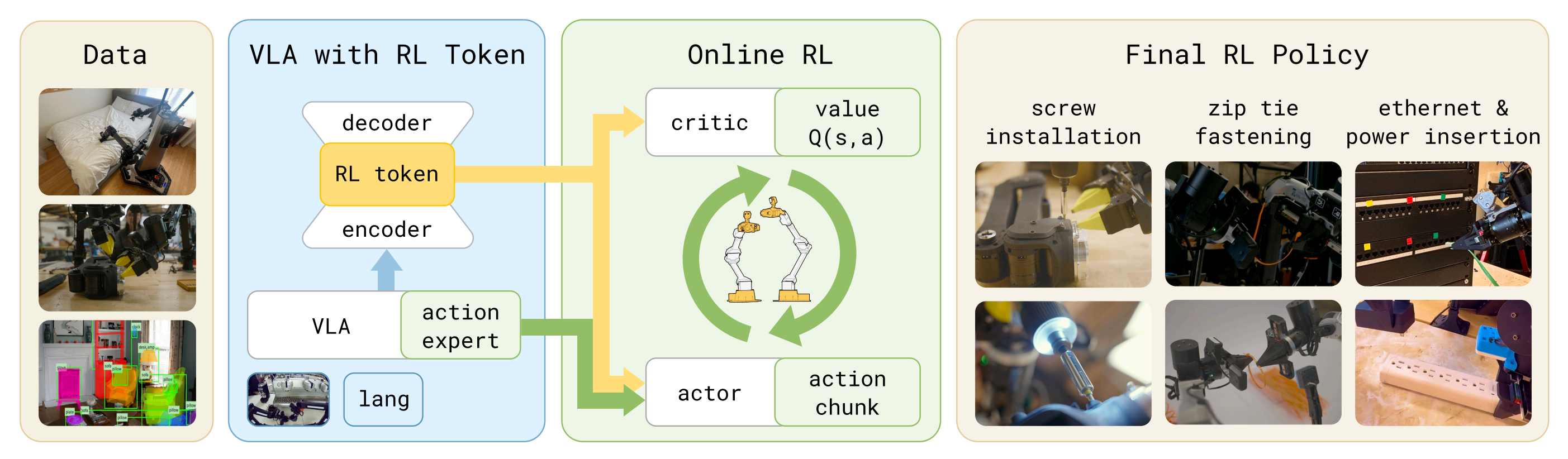
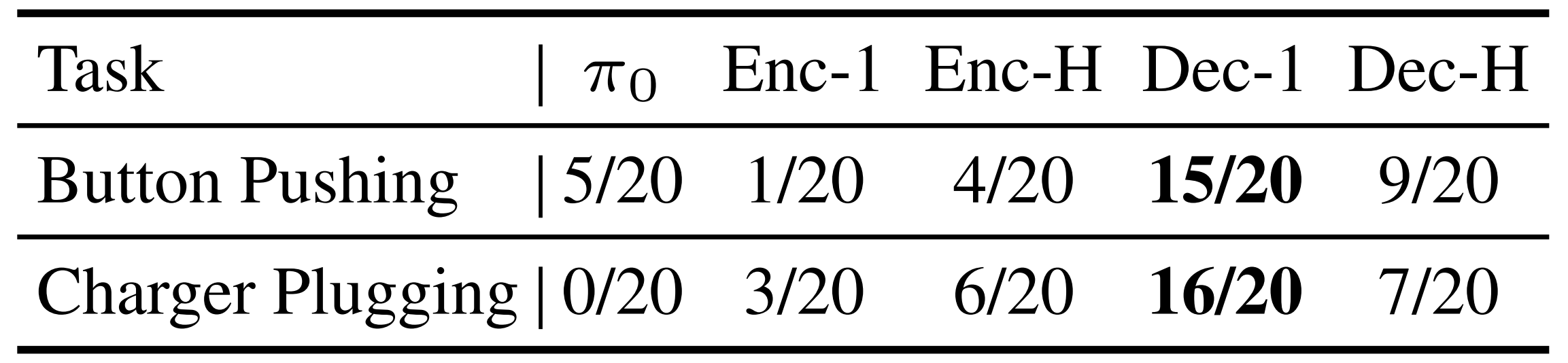
本文讨论了一种轻量级的在线强化学习方法,用于微调视觉-语言-动作模型。研究者通过引入“RL token”提高样本效率,使得模型能够快速适应真实世界任务。该方法结合冻结的VLA和小型actor-critic网络,优化关键任务阶段的表现,旨在实现高效的在线微调,同时保持泛化能力。
本文探讨了一种双执行体强化学习框架,结合人类反馈优化视觉-语言-动作(VLA)模型。通过“对话与微调”机制,机器人在长时域操作中实现高效学习,成功率达到100%。该方法在多任务设置中展现出良好的样本效率和训练稳定性,适用于复杂的机器人操作任务。
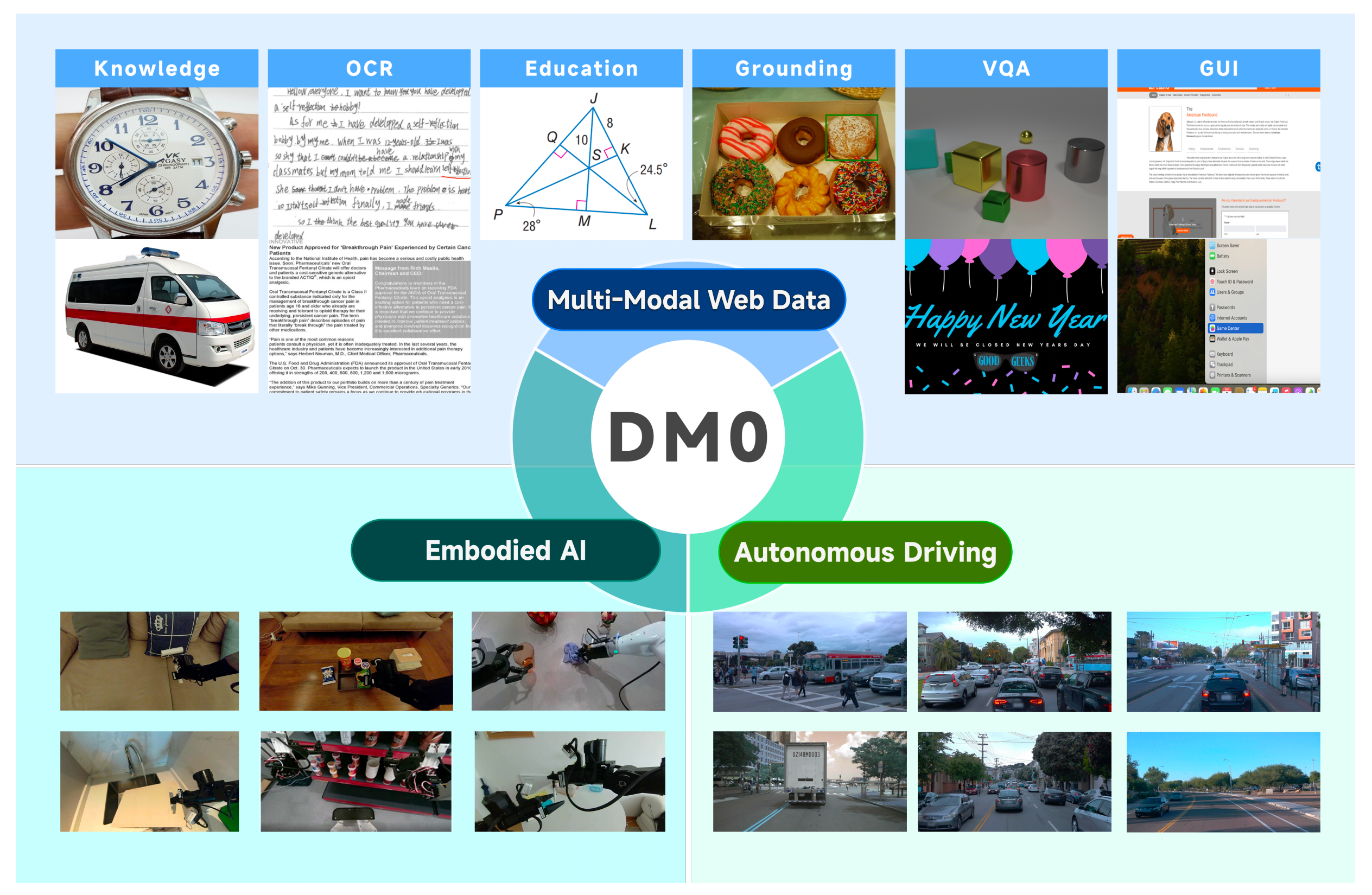
本文介绍了DM0模型,这是一种面向体感智能的视觉-语言-动作(VLA)框架,旨在统一操作与导航。DM0通过多源三阶段训练流程,结合视觉、驾驶和体感数据,克服了传统模型的局限性,并在RoboChallenge基准测试中表现优异,展示了其在物理AI领域的潜力。
RISE是一个通过想象进行机器人强化学习的框架,旨在提升视觉-语言-动作模型在复杂任务中的鲁棒性。它结合动力学预测和价值估计,利用组合式世界模型生成高效学习信号,表现优于传统强化学习方法,能够有效应对动态适应性和精确性要求的任务。
本文介绍了GigaBrain-0.5M*模型,该模型通过世界模型增强了视觉-语言-动作(VLA)系统的能力。GigaBrain-0.5M*在GigaBrain-0.5的基础上,采用了基于世界模型的强化学习方法RAMP,显著提升了机器人在复杂任务中的表现,尤其在长时程任务中的前瞻性规划能力。
GigaBrain-0是一种新型视觉-语言-动作(VLA)模型,旨在通过整合视觉输入、自然语言指令和运动控制,提升机器人在多样环境中的操作能力。该模型利用生成的数据,降低对真实世界数据的依赖,提高泛化能力和数据效率。GigaBrain-0采用混合架构,增强空间感知能力,并通过生成中间推理步骤,模拟人类问题解决过程,实现更精确的操作和决策。
本文探讨了通过残差强化学习提升视觉-语言-动作模型的自我改进能力,提出了一种名为PLD的方法,包含在线专家获取、自动数据收集和监督微调三个阶段。该方法结合基础策略和强化学习专家,成功率超过99%。
本文探讨了视觉语言动作(VLA)与强化学习(RL)结合的必要性,提出了GR-RL框架,以提高机器人在长时域操作中的灵巧性和精确度。GR-RL通过离线RL过滤次优数据,增强动作并进行在线RL调整,解决了人类示范中的噪声和不匹配问题。尽管GR-RL在高精度任务中表现出色,但仍面临行为漂移等局限性。
本文讨论了改进版的π0.5及其在视觉-语言-动作(VLA)模型中的应用,强调知识隔离策略在保持VLM预训练能力的同时,解决模态差距和数据稀缺问题。通过引入专家混合架构,WALL-OSS模型增强了跨模态关联能力,提高了指令遵循和长时序任务的成功率。
本文探讨了将关节力矩信号融入视觉-语言-动作(VLA)模型的设计,以提升机器人在物理交互中的表现。研究表明,将即时和历史力矩信息编码为单一解码器token能取得最佳效果,结合动作和力矩的预测任务可进一步增强模型性能。实验验证了该方法在高接触和常规任务中的有效性与泛化能力。
本文介绍了一种结合强化学习与视觉-语言-动作模型的微调方法ConRFT,旨在提升机器人任务的样本效率和安全性。ConRFT通过离线和在线两个阶段,利用人类示范数据和一致性策略,解决了传统方法在真实环境中的挑战,增强了智能机械臂的精准性和泛化能力。
本文介绍了G0双系统模型,结合视觉-语言-动作(VLA)与多模态规划,提出Galaxea开放世界数据集,旨在提升机器人在复杂任务中的自主感知与执行能力。该数据集包含500小时高保真数据,涵盖150个任务,确保数据一致性与可靠性。G0模型通过三阶段训练策略优化机器人性能,推动具身模型的发展。
谷歌DeepMind推出了Gemini Robotics On-Device,这是一个可在机器人硬件上本地运行的视觉-语言-动作基础模型,具备低延迟推理能力,适合本地应用。该模型是Gemini Robotics系列的最新版本,旨在解决延迟和连接性问题,并通过SDK支持开发者定制。
自6月以来,团队在机器人领域快速推进,开发了SmolVLA模型,以提升机器人在新环境中的适应能力。该模型结合视觉、语言和动作(VLA),优化了训练和推理效率,并利用社区数据进行预训练,展现出强大的泛化能力和性能。
HybridVLA是一种新型视觉-语言-动作模型,结合自回归和扩散策略,旨在提升机器人在动态环境中的操作能力。通过协同训练,该模型有效整合两种生成方法的优势,提高了动作预测的准确性和鲁棒性,并在多样化数据集上展现出优越的性能。
本研究提出了一种新颖的视觉-语言-动作架构OPAL,解决了机器人控制中的因果理解缺失问题。实验结果表明,OPAL在复杂操作任务上优于传统方法,显著提升了零样本性能,并减少了42%的推理计算需求。
谷歌DeepMind今天发布了一系列新的Gemini模型,专为机器人设计。Gemini Robotics是一个视觉-语言-动作模型,能够将自然语言和图像转化为机器人动作。Gemini Robotics-ER模型增强了识别3D空间中物体及其部件的能力,使机器人能够完成折纸、打包午餐等任务。
本研究提出了一种视觉-语言-动作(VLA)方法,以解决无人机在复杂赛车环境中的自主导航问题。研究表明,RaceVLA在高速场景中表现优异,对提升赛车导航具有重要意义。
CogACT是一种结合视觉、语言和动作的模型,通过VLM和DiT模块提升机器人在复杂任务中的表现。它提取认知信息并利用扩散模型预测动作,实现高精度和多模态的动作生成,显著提高任务成功率。
完成下面两步后,将自动完成登录并继续当前操作。