
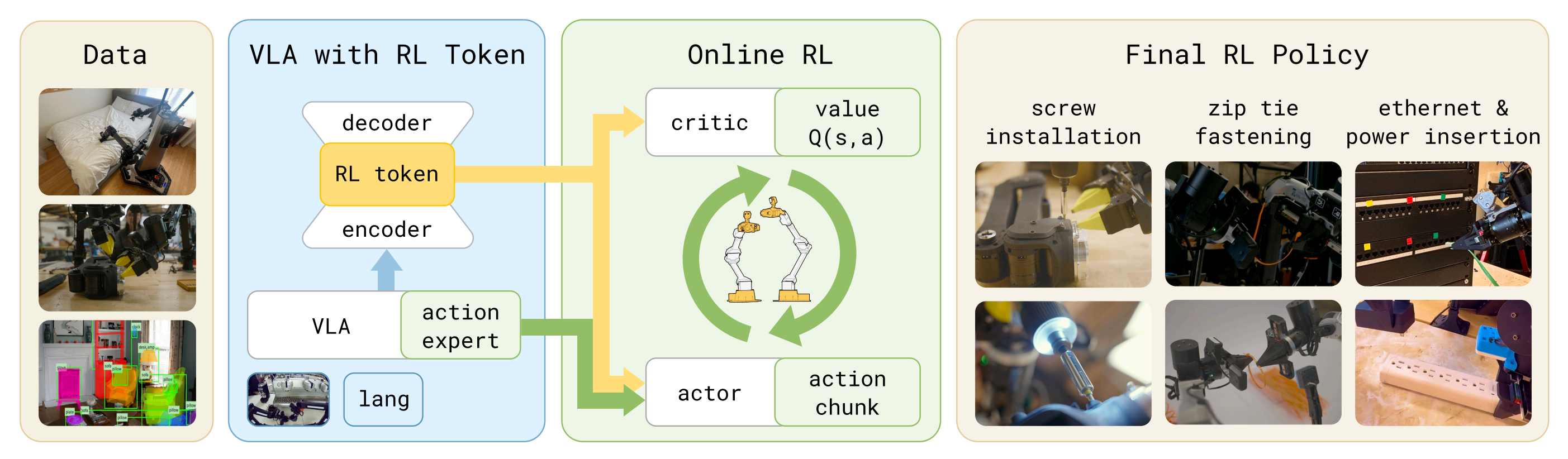
RLT——VLA引导的在线RL:极简MLP结构的Actor-Critic在“VLA浓缩Token感知与VLA参考动作先验”的双重加持下进行在线快速微调,最终从粗到细搞定拧螺丝和充电器插入
内容提要
本文讨论了一种轻量级的在线强化学习方法,用于微调视觉-语言-动作模型。研究者通过引入“RL token”提高样本效率,使得模型能够快速适应真实世界任务。该方法结合冻结的VLA和小型actor-critic网络,优化关键任务阶段的表现,旨在实现高效的在线微调,同时保持泛化能力。
关键要点
-
VLA模型在执行多样操作技能时需要进一步微调以达到实际应用的精度和速度。
-
研究者提出了一种轻量级的在线强化学习方法,通过引入'RL token'提高样本效率。
-
RL token是一种紧凑的读出表征,能够保留预训练知识并作为在线RL的高效接口。
-
该方法结合冻结的VLA和小型actor-critic网络,优化关键任务阶段的表现。
-
目标是实现高效的在线微调,同时保持VLA的泛化能力。
延伸解读
VLA模型的微调挑战
尽管VLA模型在多样操作技能上表现出色,但在实际应用中仍需微调以提高精度和速度。特别是在执行关键任务阶段,微小的错误可能导致失败,因此采用强化学习进行精细调整显得尤为重要。
RL Token的创新意义
引入RL token作为紧凑的读出表征,能够有效保留预训练知识并提升在线强化学习的样本效率。这一创新使得即使是大型VLA模型也能在短时间内进行高效微调,适应复杂的真实世界任务。
在线强化学习的实用性
该研究提出的轻量级在线强化学习方法,结合冻结的VLA和小型actor-critic网络,旨在实现快速适应。这种方法在样本利用率至关重要的场景中,能够有效降低实验成本,提高机器人系统的实用性。
延伸问答
什么是RL token,它的作用是什么?
RL token是一种紧凑的读出表征,能够保留与任务相关的预训练知识,并作为在线强化学习的高效接口。
该研究提出的在线强化学习方法有什么优势?
该方法通过引入RL token,提高了样本效率,使得模型能够在短时间内快速适应真实世界任务。
VLA模型在实际应用中面临哪些挑战?
VLA模型在执行精确任务时,往往在最后阶段表现不佳,容易出现小错误导致失败。
如何实现对VLA模型的高效微调?
通过结合冻结的VLA和小型actor-critic网络,利用RL token进行在线强化学习,从而实现高效微调。
该方法如何保持VLA的泛化能力?
通过在已有的潜在有效行为基础上进行细化,而不是从零开始学习,从而保持VLA的泛化能力。
该研究的目标是什么?
目标是实现高效的在线微调,同时保持VLA的泛化能力,以适应真实世界的任务需求。
