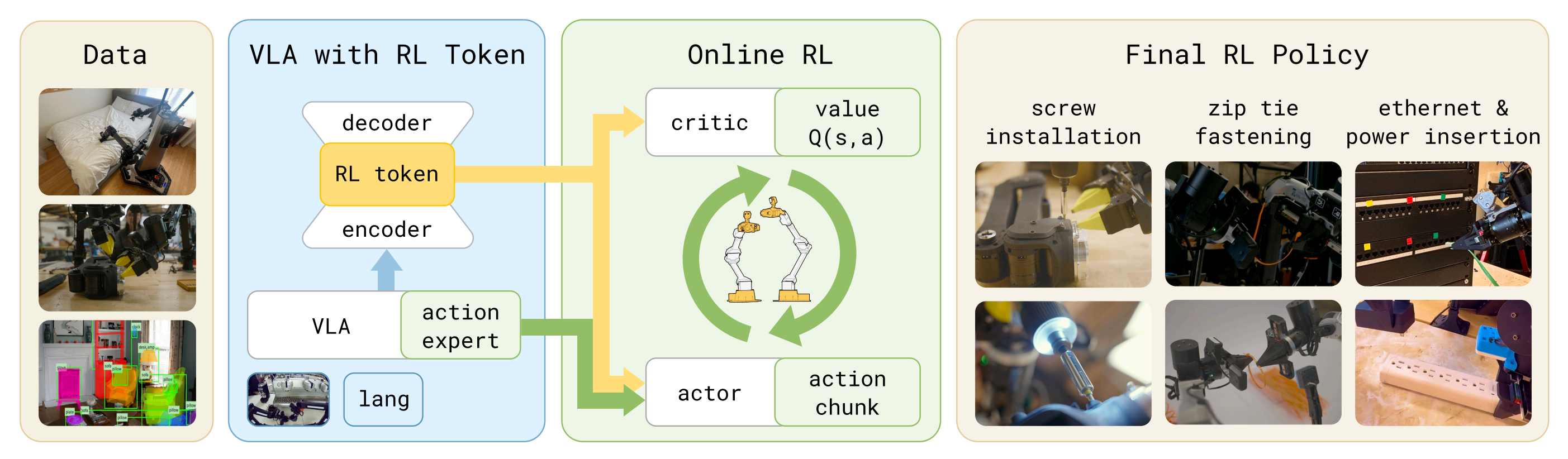
本文讨论了一种轻量级的在线强化学习方法,用于微调视觉-语言-动作模型。研究者通过引入“RL token”提高样本效率,使得模型能够快速适应真实世界任务。该方法结合冻结的VLA和小型actor-critic网络,优化关键任务阶段的表现,旨在实现高效的在线微调,同时保持泛化能力。
本文介绍了一种结合强化学习与视觉-语言-动作模型的微调方法ConRFT,旨在提升机器人任务的样本效率和安全性。ConRFT通过离线和在线两个阶段,利用人类示范数据和一致性策略,解决了传统方法在真实环境中的挑战,增强了智能机械臂的精准性和泛化能力。
本文探讨了现实世界机器人强化学习的挑战与解决方案,介绍了开源框架SERL,旨在提高样本效率并支持多任务。SERL结合高效算法RLPD,提供奖励函数设计和自动重置机制,促进机器人学习的应用。
本文介绍了RLPD和RLDG两种强化学习方法,强调利用离线数据提升在线学习效率。RLPD通过对称采样结合离线数据,提高样本效率,有效解决高维状态和稀疏奖励问题。研究表明,合理设计采样和归一化策略能显著改善学习性能。
离散扩散是一种有效的离散数据建模与生成框架。本文提出目标混凝土评分匹配(TCSM),作为训练和微调离散扩散模型的新目标。TCSM支持从数据样本进行预训练,并可结合奖励函数或偏好数据进行后期训练。实验结果表明,TCSM在语言建模任务中表现优异,具备灵活性和样本效率。
本研究提出了一种两阶段训练策略,通过预热和强化学习,解决了大型语言模型在高质量训练数据稀缺情况下的推理能力问题,显著提升了模型的推理能力和样本效率。
本研究提出了NCDPO框架,旨在解决扩散策略在决策场景中因示范数据的亚最优和有限覆盖导致的次优轨迹生成问题。通过将扩散策略重构为噪声条件下的确定性策略,实现了可追踪的似然评估和梯度反向传播,显著提高了样本效率,并在多项基准测试中优于现有方法。
本文提出了一种新方法IN-RIL,旨在解决模仿学习与强化学习结合中的不稳定性和样本效率低下的问题。通过定期注入模仿学习更新,IN-RIL提高了探索效率,实验结果表明其在多任务中显著提升了样本效率,并减少了性能崩溃现象。
本文提出了一种生成式端到端求解器,针对黑箱组合优化问题,旨在提高样本效率和解的质量。该方法基于退火算法,训练神经网络以建模玻尔兹曼分布,并在有限和无限查询预算下验证其在组合任务中的表现。
本研究提出了一种新的离散时间高斯过程混合模型(MiDiGap),用于机器人策略学习。该模型仅需五个演示和摄像头观察即可快速学习,在多项复杂任务中表现出色,显著提高了策略成功率和样本效率,具有重要的实用价值。
本研究提出了一种基于空因果的交互定义,结合交互与后见重标定(HInt),显著提升了动态机器人环境中目标条件强化学习的样本效率,最高可达4倍。
本研究提出了一种新方法,解决了离散因素化行动空间中组合行动集大的挑战。通过对Q函数的降维投影分析,确保了Q函数的无偏性,并引入了行动分解的强化学习框架,显著提升了样本效率。
本文提出了一种通过设定轨迹总回报上限来优化条件风险价值(CVaR)的方法,旨在解决现有策略梯度方法中因大量丢弃轨迹而导致的样本效率低下问题。实验结果表明,该方法在多个环境中显著提升了性能。
本研究提出了一种新颖的模型内部置信度估计器(MICE),用于校准工具使用代理的置信度。MICE通过解码语言模型的中间层来评估置信度,显著提高了工具调用的效率和置信度,具备高样本效率和零次泛化能力,适用于不同风险场景。
本研究提出了一种名为“代码作为生成性拟态(CoGA)”的方法,旨在提高强化学习代理在稀疏奖励和大行动空间环境中的样本效率。通过利用预训练的视觉-语言模型生成代码,CoGA限制了代理的行动空间,从而提升学习效率。研究结果表明,CoGA在多个任务上表现出更高的样本效率。
本研究提出Kimina-Prover Preview,旨在提高传统形式定理证明的效率。该模型模仿人类解题策略,在miniF2F基准测试中表现达到80.7%,展现出良好的样本效率和可扩展性,具有在形式验证与非正式数学直觉之间架起桥梁的潜力。
本研究提出了一种新颖的架构,通过优先记忆模块在无监督下发现重要的长尾轨迹,解决了传统强化学习算法在处理Zipfian分布时的不足,从而提高样本效率并显著提升性能。该方法可集成至任意强化学习架构,优于传统方法。
本研究提出了一种基于ODE的增强采样方法RX-DPM,旨在降低扩散概率模型生成高质量样本的计算成本,同时显著提升样本估计精度和采样效率。
本研究提出了一种名为RIG的端到端通用政策,旨在提升嵌入式代理在复杂开放世界中的推理与想象能力。通过协同学习,RIG显著提高了样本效率和泛化能力,增强了政策的鲁棒性和互操作性。
本研究提出了一种基于对抗数据增强的离线强化学习模型MORAL,旨在解决静态数据下策略开发的稳健性问题。实验结果表明,MORAL在政策学习和样本效率方面优于传统方法,具有广泛的适用性。
完成下面两步后,将自动完成登录并继续当前操作。