

DynaMiCS:使用动态混合进行具有性能约束的大型语言模型微调
Apple Machine Learning Research
·

进入全宇宙:通过合成数据和微调提高视觉AI代理准确性的三种工作流程
NVIDIA Blog
·

1小时真机RL微调成功率破95%!HIL-ResRL:即插即用的VLA“外挂”神器
mongona news
·


步骤拒绝微调:从嘈杂的智能体轨迹中提取更多信号
The JetBrains Blog
·

《GPT 图解》笔记:微调与RLHF、总结
Ying’s Blog
·

针对视频智能的多模态模型微调
Mux Blog - Video technology and more
·
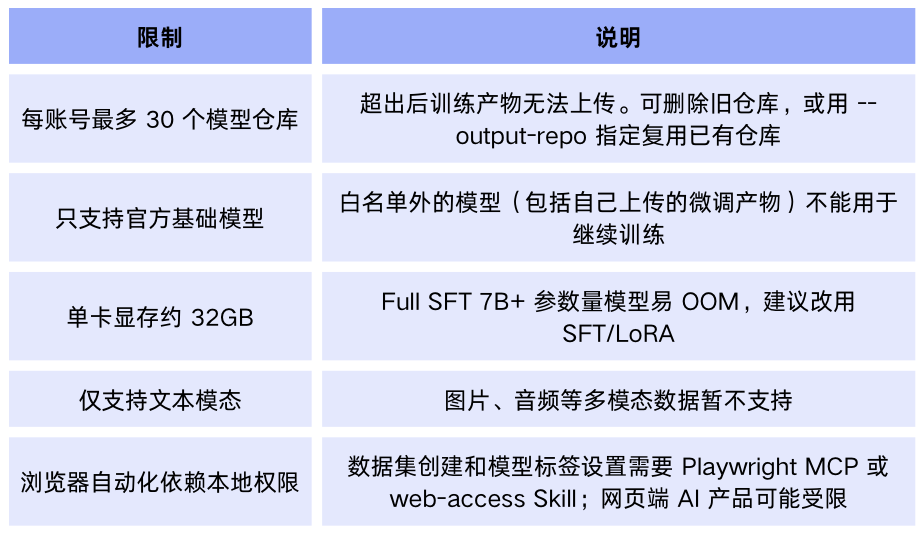

AI论文评审:通过生成预训练(GPT-1)提升语言理解
freeCodeCamp.org
·
