
在Amazon SageMaker AI和Amazon Bedrock上高效服务数十个微调模型与vLLM
内容提要
为解决多模型AI服务的闲置GPU成本问题,我们与vLLM社区合作开发了Multi-LoRA技术,允许多个模型共享同一GPU,优化MoE模型的推理性能。该技术通过保持原始权重不变,仅调整小型适配器,显著提升了输出速度并降低了延迟,适用于多个开源MoE模型,并已在Amazon SageMaker和Bedrock上实现。
关键要点
-
为解决多模型AI服务的闲置GPU成本问题,开发了Multi-LoRA技术,允许多个模型共享同一GPU。
-
Multi-LoRA通过保持原始权重不变,仅调整小型适配器,显著提升了输出速度并降低了延迟。
-
该技术适用于多个开源MoE模型,并已在Amazon SageMaker和Bedrock上实现。
-
MoE模型通过路由将输入令牌分配给相关专家,处理更大的模型而消耗更少的计算资源。
-
Multi-LoRA在推理时允许多个自定义模型共享同一GPU,仅在请求时交换适配器。
-
vLLM使用fused_moe内核执行投影操作,Multi-LoRA保持基础模型权重不变,训练小型矩阵作为适配器。
-
在多LoRA服务设置中,系统必须高效管理每个专家、每个适配器的四个操作。
-
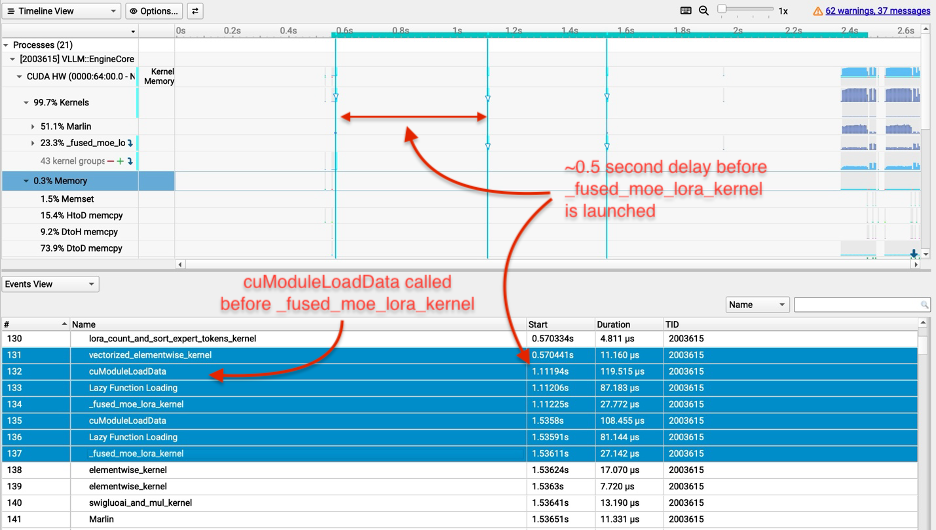
为解决技术挑战,创建了fused_moe_lora内核,将LoRA操作集成到fused_moe内核中。
-
通过NVIDIA Nsight Systems和NVIDIA Nsight Compute识别瓶颈并进行优化,显著提高了性能。
-
优化后的Multi-LoRA在vLLM 0.15.0中实现了454%的OTPS提升和87%的TTFT降低。
-
Amazon特定的优化进一步提高了模型的延迟性能,例如GPT-OSS 20B的OTPS提高了19%。
-
用户可以在Amazon SageMaker AI或Amazon Bedrock上托管LoRA定制模型,享受这些优化。
延伸解读
Multi-LoRA技术的优势
Multi-LoRA技术通过允许多个模型共享同一GPU,显著降低了闲置GPU的成本。这种方法特别适合流量不均的场景,能够有效提升资源利用率,减少企业在AI服务上的开支。
技术挑战与解决方案
在实现Multi-LoRA时,面临着处理稀疏性和适配器选择的复杂性。为此,开发了fused_moe_lora内核,集成了LoRA操作,优化了性能。这一创新解决了多模型服务中的关键瓶颈,提升了推理速度。
优化效果显著
通过对vLLM的优化,Multi-LoRA在推理性能上实现了454%的OTPS提升和87%的TTFT降低。这些改进不仅适用于MoE模型,也对密集模型的性能提升有显著效果,展示了技术的广泛适用性。
延伸问答
什么是Multi-LoRA技术?
Multi-LoRA技术允许多个模型共享同一GPU,通过保持原始权重不变,仅调整小型适配器,优化推理性能。
Multi-LoRA如何解决GPU闲置成本问题?
Multi-LoRA通过让多个模型共享同一GPU,减少了因单个模型流量不足而导致的闲置GPU成本。
在Amazon SageMaker和Bedrock上使用Multi-LoRA有什么优势?
在Amazon SageMaker和Bedrock上使用Multi-LoRA可以享受优化后的推理性能,如更高的输出速度和更低的延迟。
Multi-LoRA技术的优化效果如何?
优化后的Multi-LoRA在vLLM 0.15.0中实现了454%的OTPS提升和87%的TTFT降低。
MoE模型的工作原理是什么?
MoE模型通过路由将输入令牌分配给相关专家,处理更大的模型而消耗更少的计算资源。
如何在本地部署Multi-LoRA?
用户可以在本地使用vLLM 0.15.0或更高版本来部署Multi-LoRA。
