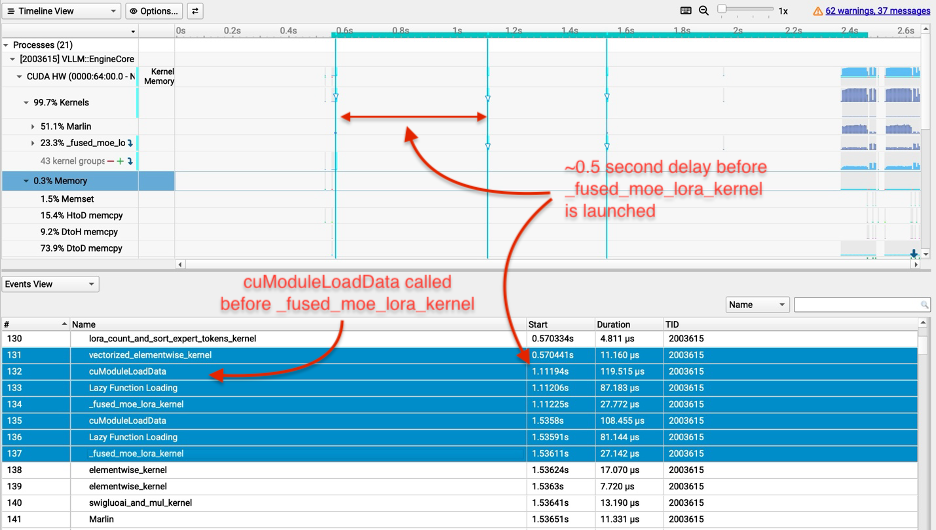
OpenAI与博通推出优化大语言模型推理的芯片
OpenAI
·

动态批处理:实用指南
Redis Blog
·

推理阿尔法:在AMD上最大化前沿模型
The DigitalOcean Blog
·
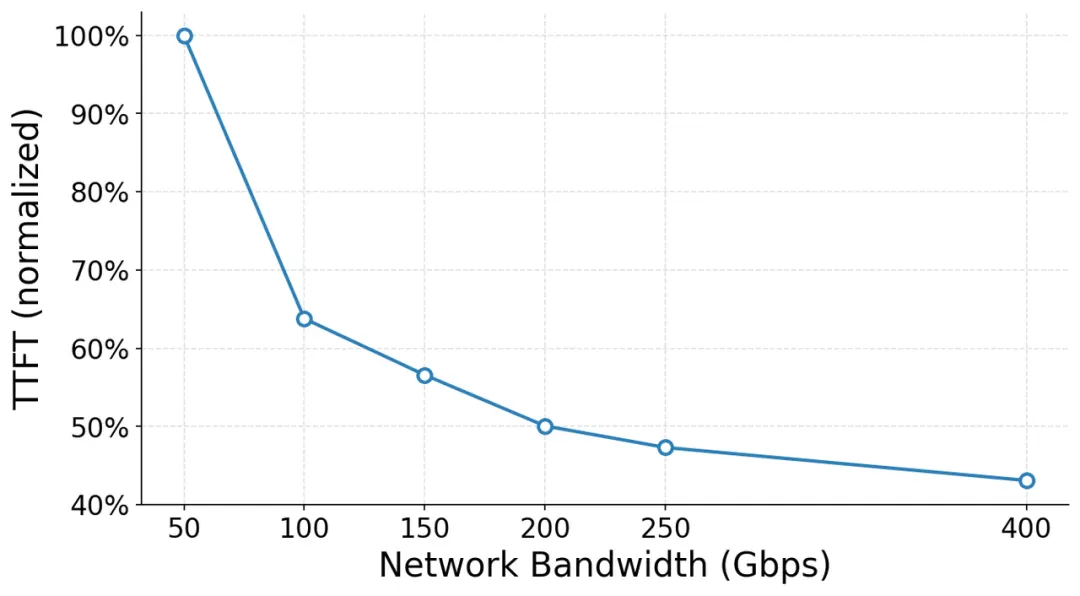
下一代大模型推理网络架构:ZCube如何有效破解网络瓶颈?
实时互动网
·

我们如何在DigitalOcean NVIDIA HGX™ B300 GPU Droplets上构建最具性能的DeepSeek V3.2、MiniMax-M2.5和Qwen 3.5 397B
The DigitalOcean Blog
·
DeepSeek-V4发布,华为云首发适配
量子位
·

迎接高性能、低成本推理的新标准:NVIDIA Dynamo 1.0现已向DigitalOcean客户开放
The DigitalOcean Blog
·

DigitalOcean的Agentic推理云如何通过NVIDIA GPU为Workato实现67%的推理成本降低
The DigitalOcean Blog
·