
SemiAnalysis InferenceMAX:vLLM与NVIDIA加速Blackwell推理
内容提要
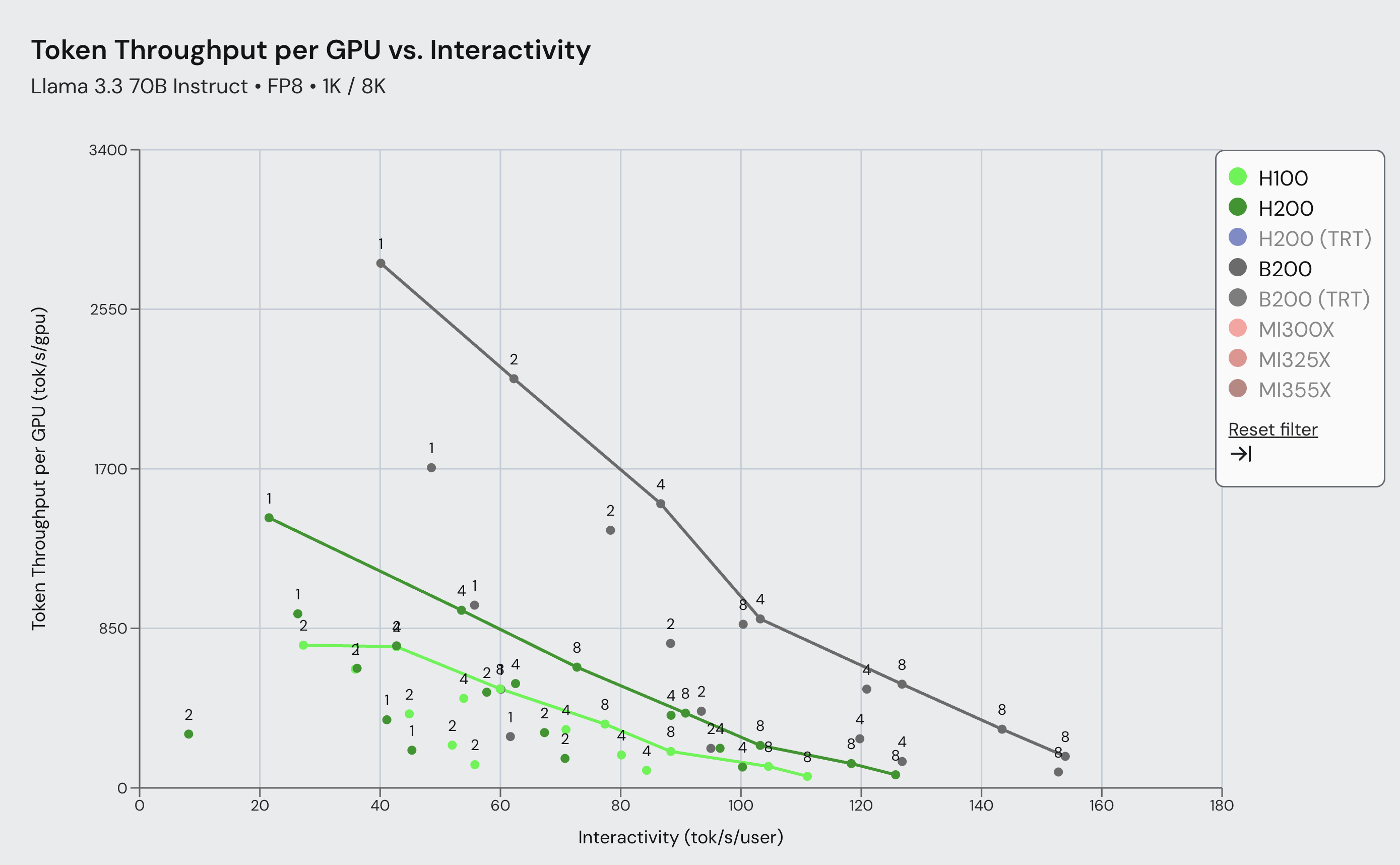
与NVIDIA合作,优化Blackwell GPU架构以提升大语言模型的推理性能。通过重构和开发新内核,vLLM在Blackwell上实现了最高4倍的吞吐量提升,显著提高了推理效率。新基准测试显示,Blackwell在多种交互场景下表现优异,持续推动推理性能提升。
关键要点
-
与NVIDIA合作,优化Blackwell GPU架构以提升大语言模型的推理性能。
-
通过重构和开发新内核,vLLM在Blackwell上实现了最高4倍的吞吐量提升。
-
新基准测试显示,Blackwell在多种交互场景下表现优异,持续推动推理性能提升。
-
SemiAnalysis InferenceMax是一个自动化基准框架,用于评估LLM服务性能。
-
基准测试涵盖了多种输入/输出长度场景,以模拟真实使用情况。
-
Blackwell的计算架构结合了最新的HBM3e内存和高NVLink数据传输速度。
-
优化工作涉及软件栈的各个层面,包括内核执行速度和CPU开销的减少。
-
集成NVIDIA的FlashInfer库以提高内核性能,结合多种高性能内核。
-
vLLM自动检测模型的量化情况并选择合适的后端,简化用户操作。
-
持续的优化和与NVIDIA的合作将推动Blackwell平台的效率和规模。
-
感谢vLLM社区和NVIDIA团队的贡献,推动硬件和开源软件的共同设计。
延伸问答
vLLM如何提升Blackwell GPU的推理性能?
vLLM通过重构现有内核和开发新内核,优化了Blackwell GPU架构,实现了最高4倍的吞吐量提升。
SemiAnalysis InferenceMAX是什么?
SemiAnalysis InferenceMAX是一个自动化基准框架,用于评估大语言模型服务性能,结果每日更新。
Blackwell GPU的计算架构有哪些新特性?
Blackwell GPU结合了最新的HBM3e内存和高NVLink数据传输速度,支持FP4精度格式。
vLLM如何简化用户操作?
vLLM自动检测模型的量化情况并选择合适的后端,简化了用户的操作流程。
与NVIDIA的合作对推理性能有何影响?
与NVIDIA的合作推动了Blackwell平台的效率和规模,优化了几乎每个推理管道的部分。
基准测试中使用了哪些模型?
基准测试使用了gpt-oss 120B和Llama 3.3 70B这两个开源模型。
