
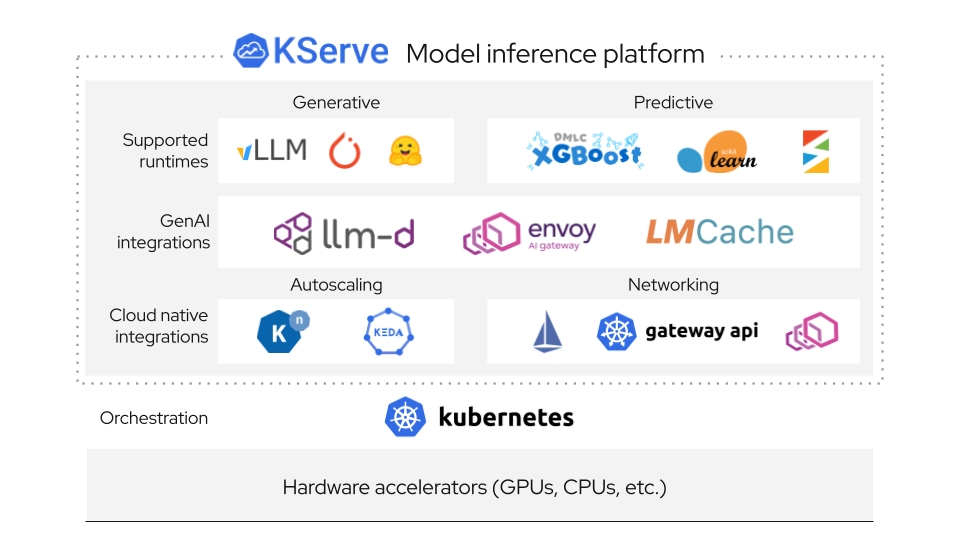
KServe 入门:部署第一个 vLLM 推理服务
探索云原生
·

在Kubernetes中使用vLLM运行自托管的大型语言模型(LLM)
Cloud Native Computing Foundation
·


vLLM的Rust前端PR了,预处理吞吐量直接翻了5倍!
迷途小书童
·
使用vLLM + Qwen3.5部署内网AI笔记
tlanyan
·

理解 KV Cache:Attention、P/D 分离与 vLLM 的页式显存管理
Steins;Lab
·

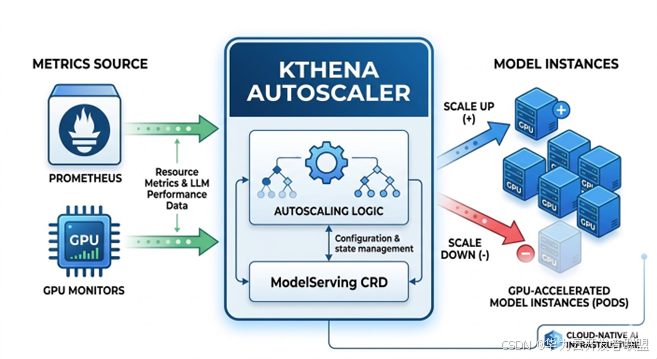
Kthena + vLLM-Ascend:云原生大模型推理的编排与调度实践
华为云官方博客
·


vLLM 部署 GLM-5 实践指南
探索云原生
·
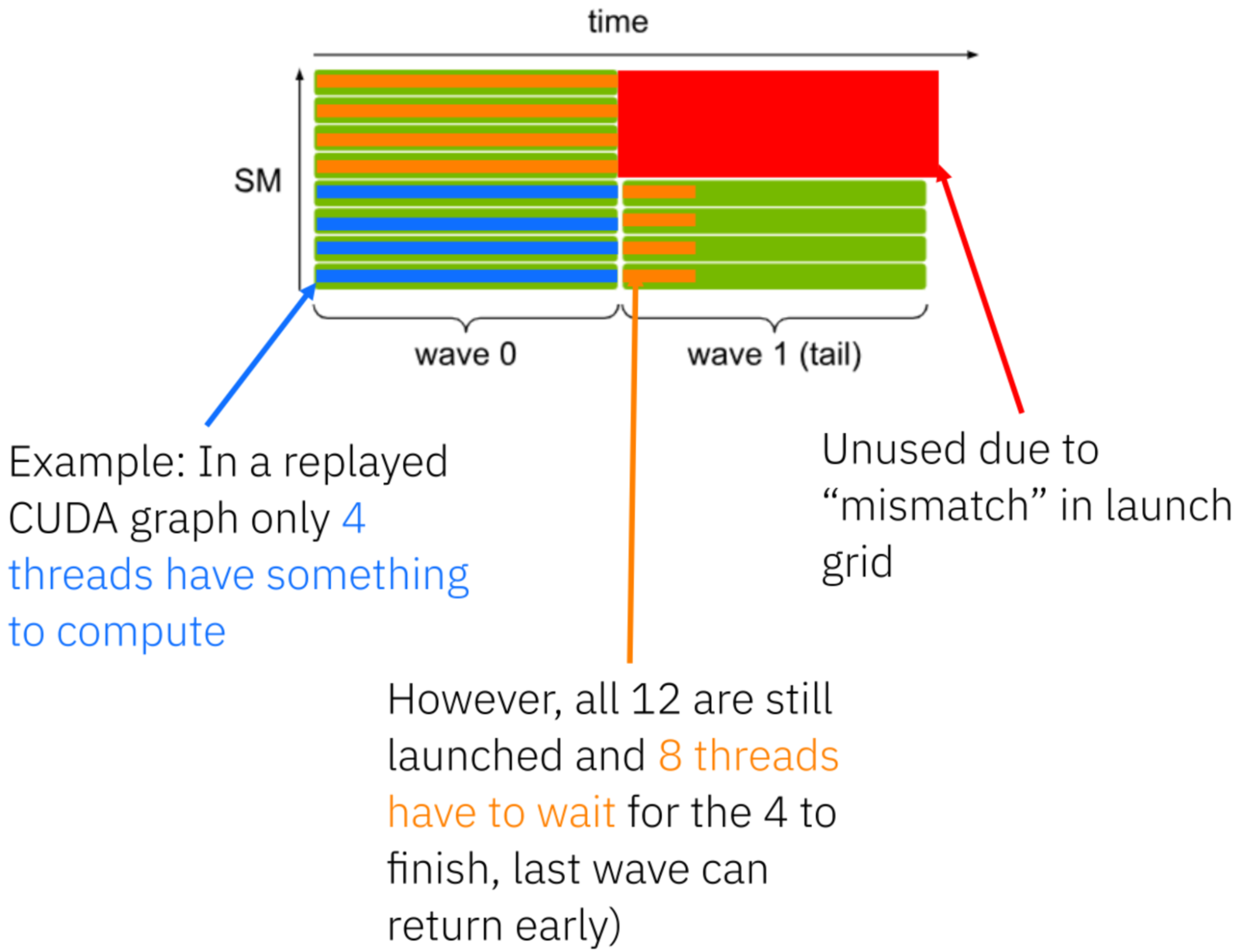
vLLM Triton 注意力后端深度解析
vLLM Blog
·
