
超越移植:vLLM如何在AMD ROCm上协调高性能推理
内容提要
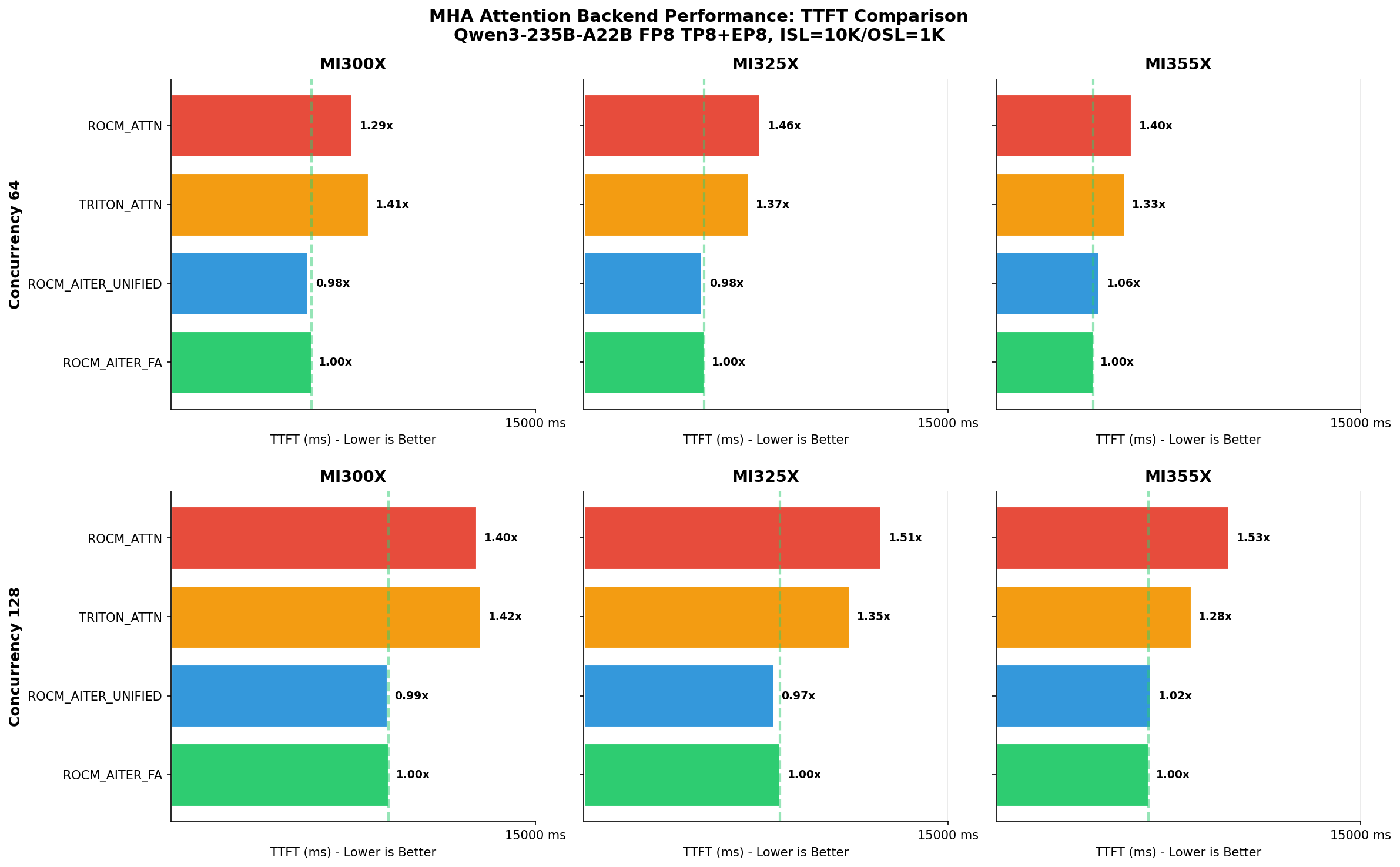
vLLM在AMD ROCm上提供七种高性能推理后端,支持复杂模型结构。ROCM_AITER_FA通过三路径路由优化混合工作负载,显著提高吞吐量,性能提升达到2.7-4.4倍,确保软件与硬件高效协作,适应多样化请求。
关键要点
-
vLLM在AMD ROCm上提供七种高性能推理后端,支持复杂模型结构。
-
ROCM_AITER_FA通过三路径路由优化混合工作负载,显著提高吞吐量,性能提升达到2.7-4.4倍。
-
ROCM_AITER_FA的三路径路由将请求动态分类为解码、预填充和扩展路径,每个路径都有优化的内核。
-
ROCM_AITER_FA的批处理重排序确保每个内核路径在连续的令牌上操作,消除冗余的KV缓存获取。
-
AITER MLA后端通过共享的汇编解码内核实现了1.2-1.6倍的速度提升,优化了内存带宽的使用。
-
vLLM的调度和AMD的AITER原语的协作是性能提升的关键,单独的优化无法达到最佳效果。
延伸解读
高性能推理的架构设计
vLLM在AMD ROCm上实现的三路径路由架构,强调了软件与硬件的协同设计。这种设计不仅提高了吞吐量,还确保了在处理混合工作负载时的灵活性。通过动态分类请求,系统能够针对不同的计算需求选择最优的内核,从而提升整体性能。
优化的内存带宽使用
ROCM_AITER_FA后端通过优化的KV缓存布局,显著提升了内存带宽的使用效率。这种布局设计减少了冗余的缓存获取,确保每个内核路径在处理连续令牌时能够高效运作。这对于需要快速响应的在线服务尤为重要,能够有效降低延迟。
适应多样化请求的能力
vLLM的调度系统能够有效处理来自不同请求类型的混合批次,这在实际应用中非常关键。通过将请求分为解码、预填充和扩展路径,系统能够在保证高吞吐量的同时,灵活应对不同的计算需求,提升了用户体验。
延伸问答
vLLM在AMD ROCm上提供了哪些推理后端?
vLLM在AMD ROCm上提供七种高性能推理后端,支持复杂模型结构。
ROCM_AITER_FA是如何优化混合工作负载的?
ROCM_AITER_FA通过三路径路由将请求动态分类为解码、预填充和扩展路径,每个路径都有优化的内核,从而优化混合工作负载。
使用vLLM时,如何选择最佳的推理后端?
推荐使用命令'export VLLM_ROCM_USE_AITER=1',让vLLM自动选择最佳的推理后端。
ROCM_AITER_FA的性能提升有多大?
ROCM_AITER_FA的性能提升达到2.7-4.4倍,显著提高了吞吐量。
ROCM_AITER_FA的三路径路由有什么优势?
三路径路由使得每种请求类型都能通过专门优化的内核处理,提高了性能和可调试性。
AITER MLA后端的速度提升是多少?
AITER MLA后端通过共享的汇编解码内核实现了1.2-1.6倍的速度提升。
