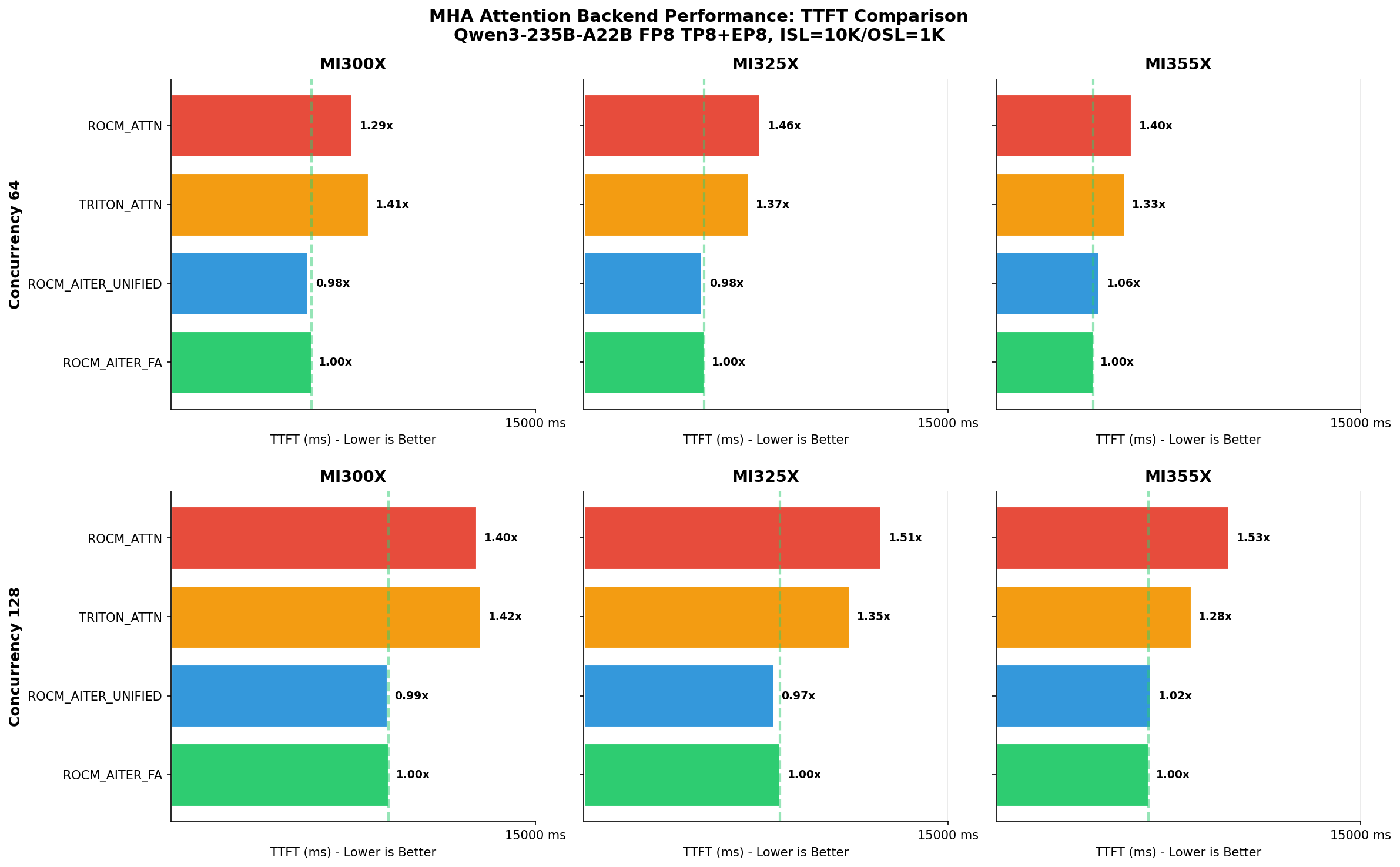
vLLM在AMD ROCm上提供七种高性能推理后端,支持复杂模型结构。ROCM_AITER_FA通过三路径路由优化混合工作负载,显著提高吞吐量,性能提升达到2.7-4.4倍,确保软件与硬件高效协作,适应多样化请求。
VLLM Benchmark 是一个测试模型性能的工具,支持多种推理后端。文章记录了模型服务和客户端的启动过程,并展示了使用随机输入和 ShareGPT 数据集进行性能测试的结果,包括请求成功率、生成的令牌数和延迟等指标。通过调整请求速率和输入长度,可以优化性能。
完成下面两步后,将自动完成登录并继续当前操作。