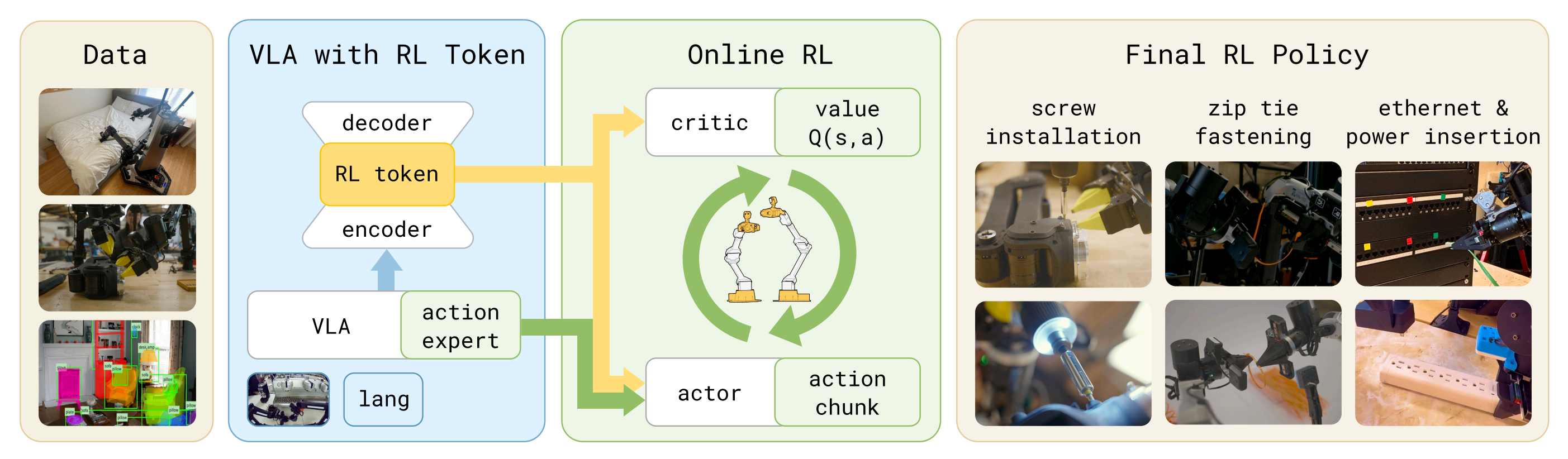
本文讨论了一种轻量级的在线强化学习方法,用于微调视觉-语言-动作模型。研究者通过引入“RL token”提高样本效率,使得模型能够快速适应真实世界任务。该方法结合冻结的VLA和小型actor-critic网络,优化关键任务阶段的表现,旨在实现高效的在线微调,同时保持泛化能力。
MetaClaw通过在线强化学习系统,使AI在与用户对话中自动学习和进化,无需GPU和数据集。用户只需简单配置,AI即可实时优化表现并生成新技能,降低了持续学习的门槛。
本文介绍了πRL框架,这是首个用于流式视觉-语言-动作模型的在线强化学习微调方法。通过结合流匹配与强化学习,πRL提升了模型的性能与泛化能力。研究者提出了Flow-Noise和Flow-SDE两种技术,增强了随机性探索,优化了训练过程,为复杂多任务机器人场景中的流式VLA微调提供了新思路。
斯坦福团队的AgentFlow系统通过在线强化学习优化智能体,显著提升推理能力,超越GPT-4o等大型模型。该系统由四个专业智能体协作,实时优化决策,尤其在知识检索和智能体任务中提升超过14%,展示了模块化设计和动态学习的重要性。
本文提出了一种结合离线强化学习与在线强化学习的方法WSRL(Warm-start RL),旨在解决微调过程中的灾难性遗忘问题。WSRL通过在在线微调初期收集少量数据,有效利用预训练知识,提升微调效率和性能,避免依赖大量离线数据。
本研究探讨如何通过在线强化学习将大型语言模型(LLMs)与有效教育法对齐,提出的框架使LLMs成为有效的导师,提升教育质量,且无需人工注释,训练出的模型在教育效果上与更大规模模型相当。
本研究提出了一种新的在线强化学习框架RISE,旨在提升大型语言模型的自我验证能力和解题准确性,从而增强推理过程,推动智能推理系统的发展。
本研究提出Flow-GRPO方法,首次将在线强化学习应用于流匹配模型,有效提升文本到图像任务的生成准确性和人类偏好对齐效果。
本研究提出了一种在线强化学习框架,解决了图像编辑扩散模型在结构保持和用户提示语义对齐方面的挑战。该方法无需大量标注,能够在复杂场景中实现真实且一致的编辑,展现了在机器人仿真环境中的应用潜力。
DeepSeek与清华大学合作发布新论文,提出SPCT方法,通过在线强化学习优化奖励模型,解决通用领域的灵活性和准确性问题。同时,奥特曼宣布GPT-5将在几个月后发布,效果超出预期。
本研究提出了一种基于视频数据的价值函数,旨在解决在线强化学习中稀疏奖励导致的反馈不足问题。该方法利用多样的数据源,展现出良好的迁移效果和泛化能力,有望提升在线强化学习的效果与效率。
本文探讨了多模态大型语言模型(MLLMs)在超越传统语言和视觉任务的能力,重点介绍了通用具身代理(GEA)的适应过程。GEA通过多具身动作标记器在不同领域自我定位,利用大规模具身经验数据集进行监督学习,并在交互式模拟器中进行在线强化学习。研究表明,跨领域数据和在线强化学习对构建通用代理至关重要,最终GEA模型在多项基准测试中表现优异,超越其他通用模型和特定基准方法。
本研究提出了一种基于在线强化学习的动态权重调整机制,解决实时策略任务评估中的适应性问题,显著提升评估函数在规划算法中的效果,尤其在大地图下计算时间增长控制在6%以内。
本研究探讨了多模态大型语言模型在传统语言和视觉任务之外的应用,提出了一种将其转化为通用具身智能体的方法。研究表明,跨域数据和在线强化学习对构建通用智能体至关重要,最终模型在新任务上展现出强大的泛化能力。
本研究提出了一种无悔的在线强化学习算法,旨在为安全关键系统在未知动态环境中合成控制器。该算法能够有效评估学习过程中接近最佳行为的程度,显著提升基于线性时序逻辑(LTL)规范的任务学习性能与效率。
本研究探讨了在线强化学习中如何在学习未知环境的同时满足安全约束,提出了针对受约束线性二次调节器的后悔界限,表明安全性提升了探索机会。
本研究提出了Diff-Instruct*模型,旨在解决文本到图像生成模型与人类偏好之间的对齐问题。通过在线强化学习和散度正则化方法,该模型显著提升了生成图像的真实感和美观度,并在多个基准测试中超越了先前的领先模型。
本文介绍了推荐系统的研究进展,包括基于用户反馈的个性化推荐、在线强化学习算法、对话情境策略推荐和多臂赌博机算法的应用。研究表明,考虑用户偏好的动态性和自反馈偏差能显著提升推荐效果,提出的算法在多个实验中优于现有方法。
本文研究了线性错误赌博机及其学习中的稀疏性,提出了一种新算法并证明其样本复杂度接近最优。同时探讨了在线强化学习中的样本复杂性及算法的上下界,提出了基于特征维度的参数 Q 学习算法,以提高样本效率。
该研究探讨了量子状态测量对量子学习的影响,提出通过正则化算法和测量副本降低预测失误率。研究表明,传统量子态重构所需测量数量呈线性增长,并提出“影子断层扫描”方法在量子应用中的实际价值。此外,论文讨论了在线强化学习和连续时间控制系统的算法性能界限。
完成下面两步后,将自动完成登录并继续当前操作。