

💡
原文中文,约600字,阅读约需2分钟。
📝
内容提要
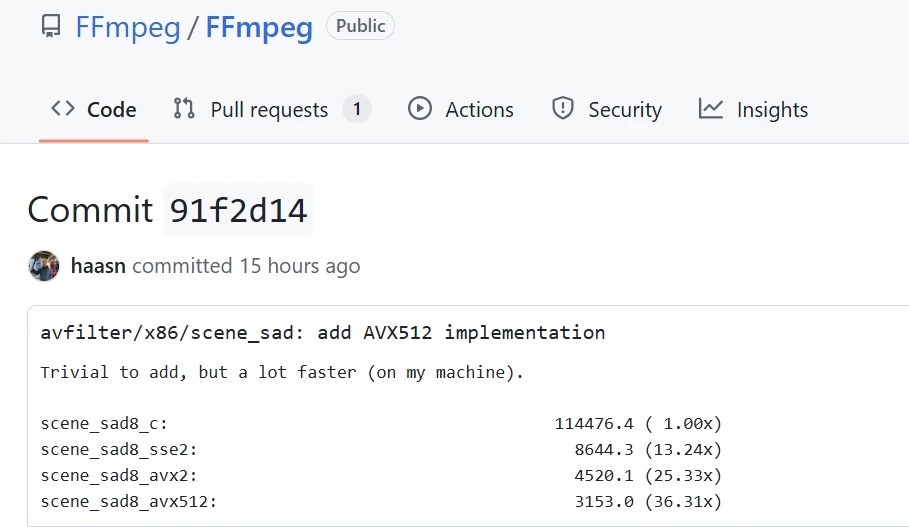
FFmpeg 最近合并了针对 AVX-512 和 AVX2 的手工优化代码,显著提升了性能。基准测试显示,使用 AVX-512 的 avfilter scene_sad 速度是普通 C 代码的 36.31 倍,AVX2 为 25 倍。高位深度版本在 AMD Zen 4/Zen 5 和 Intel Xeon 处理器上表现尤为出色。
🎯
关键要点
- FFmpeg 最近合并了针对 AVX-512 和 AVX2 的手工优化代码,显著提升了性能。
- 使用 AVX-512 的 avfilter scene_sad 速度是普通 C 代码的 36.31 倍,AVX2 为 25 倍。
- 高位深度版本在 AMD Zen 4/Zen 5 和 Intel Xeon 处理器上表现尤为出色。
- 开源多媒体开发人员 Niklas Haas 提交了额外的 AVX2 和 AVX-512 调整代码。
- FFmpeg 的 avfilter scene_sad 代码现在增加了 AVX-512 实现,性能提升显著。
- 高位深度 AVX2 和 AVX-512 版本的 scene_sad avfilter 代码性能提升约 11 倍,使用 AVX-512 时提升约 22 倍。
➡️
