
一文通透Qwen3-VL——在交错式MRoPE、DeepStack、文本时间戳对齐机制的基础上,先预训练,再后训练(即分别SFT、蒸馏、RL)
内容提要
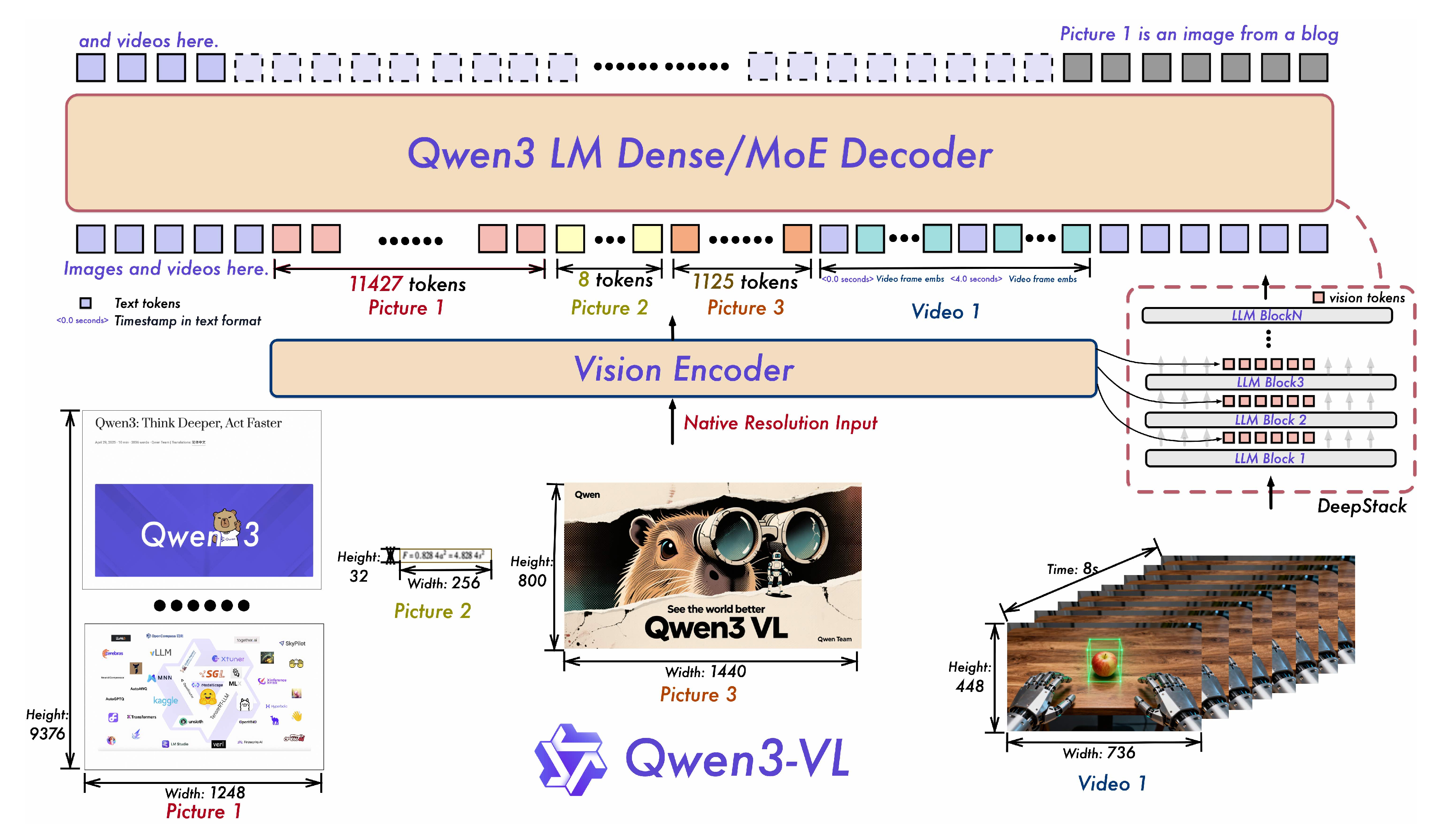
Qwen系列模型最新升级为Qwen3-VL,在视觉理解和视频处理方面有显著提升。引入多维旋转位置编码(MRoPE)和DeepStack技术,增强了对复杂场景的推理能力,支持长文档和长视频处理,具备更高的上下文长度和精确的时间定位能力,推动多模态理解的进步。
关键要点
-
Qwen系列模型最新升级为Qwen3-VL,显著提升了视觉理解和视频处理能力。
-
引入多维旋转位置编码(MRoPE)和DeepStack技术,增强了对复杂场景的推理能力。
-
支持长文档和长视频处理,具备256K token的上下文长度,最高可扩展至100万token。
-
模型在视频时序建模机制上进行了升级,提升了对视频中动作和事件的语义感知与时间定位精度。
-
训练流程经过全面革新,包含增强的图像描述监督和多样化的训练数据,以实现更强的多模态理解能力。
延伸解读
多模态理解的进步
Qwen3-VL在多模态理解方面的提升,尤其是在长文档和长视频处理能力上,标志着技术的重大进步。其支持256K token的上下文长度,意味着用户可以处理更复杂的信息,适用于教育、研究等领域。
训练流程的创新
Qwen3-VL的训练流程经过全面革新,采用了预训练和后训练的双阶段策略。这种方法不仅提高了模型的鲁棒性,还通过多样化的数据源增强了模型的适应性,适合不同应用场景。
视频时序建模的提升
新引入的文本时间戳对齐机制显著提升了模型对视频中动作和事件的语义感知能力。这一改进使得Qwen3-VL在复杂时序推理任务中表现更为精准,适合需要高精度时间定位的应用。
延伸问答
Qwen3-VL模型有哪些显著的提升?
Qwen3-VL在视觉理解和视频处理能力上有显著提升,支持长文档和长视频处理,具备256K token的上下文长度,最高可扩展至100万token。
Qwen3-VL是如何增强对复杂场景的推理能力的?
Qwen3-VL引入了多维旋转位置编码(MRoPE)和DeepStack技术,提升了视觉细节捕捉能力和图文对齐精度。
Qwen3-VL支持多长的上下文长度?
Qwen3-VL原生支持256K token的上下文长度,并可扩展至100万token。
Qwen3-VL在视频时序建模方面有哪些改进?
Qwen3-VL将视频时序建模机制升级为文本时间戳对齐机制,提升了对视频中动作和事件的语义感知与时间定位精度。
Qwen3-VL的训练流程是怎样的?
Qwen3-VL的训练流程分为预训练和后训练两个阶段,预训练包括对齐阶段和全参数训练,后训练则包括有监督微调和强化学习。
Qwen3-VL如何实现更强的多模态理解能力?
通过增强的图像描述监督、多样化的训练数据和思维链推理数据,Qwen3-VL实现了更强的多模态理解能力。
