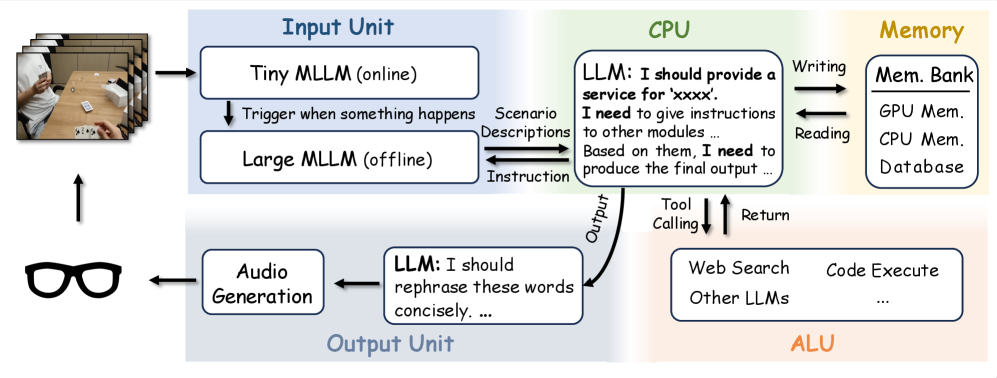
连夜实测 Kimi K3,建议改名 Kable
爱范儿
·

Kimi K3现已在AI Gateway上可用
Vercel News
·
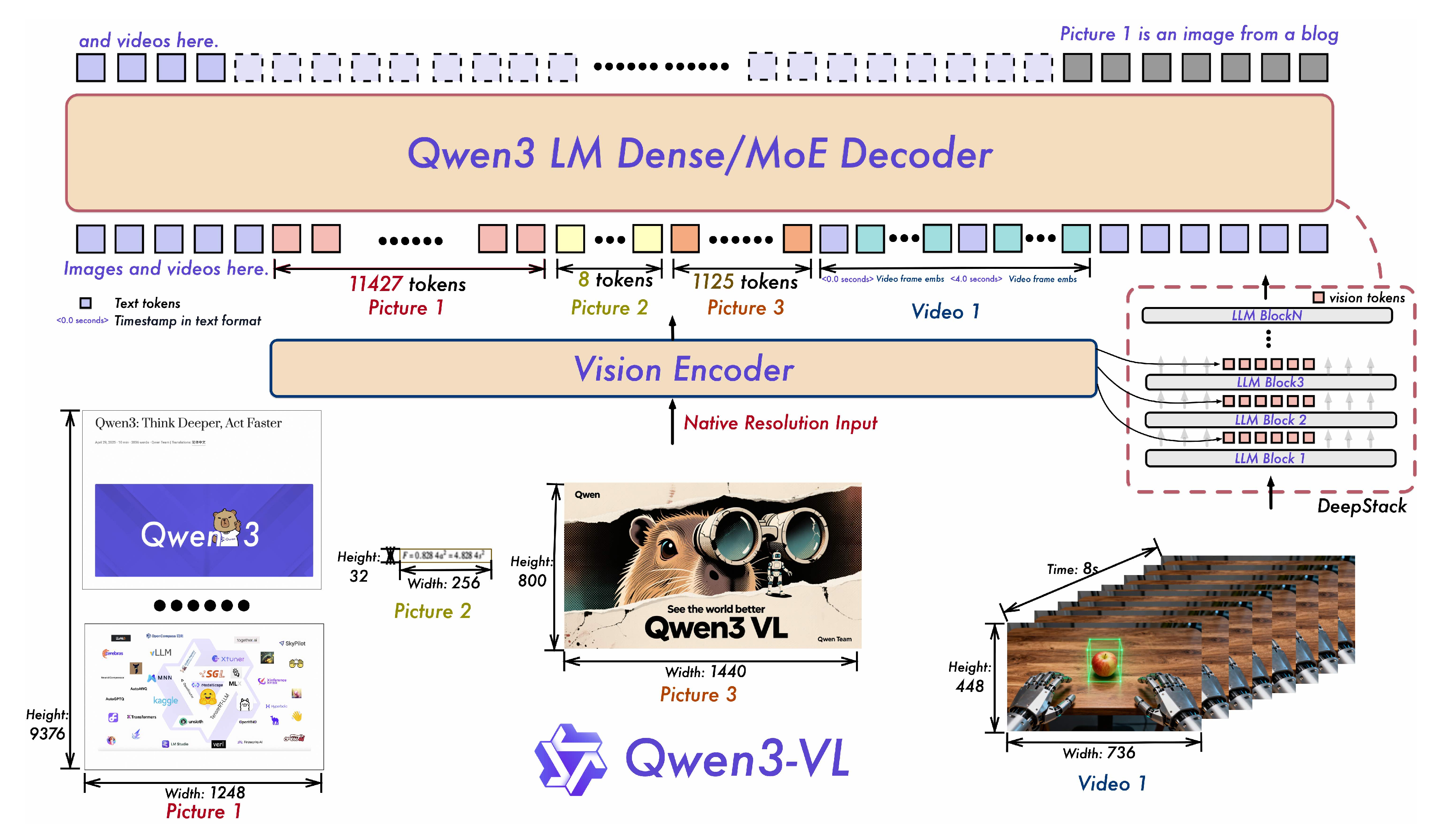

基于文本条件的JEPA用于学习语义丰富的视觉表示
Apple Machine Learning Research
·

一分钟读论文:《用扩散语言模型统一多模态理解与生成》
Micropaper
·
Kimi K2.5已在AI Gateway上线
Vercel News
·
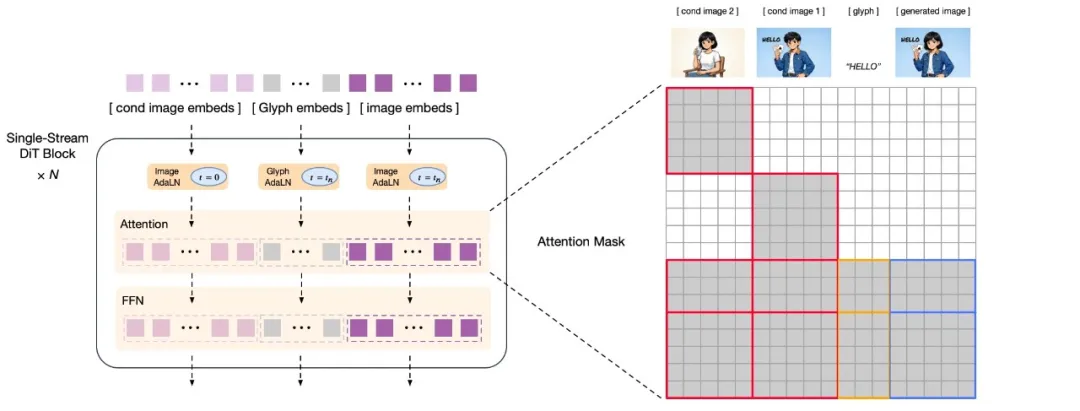
GLM-Image 上线模力方舟:首个国产芯片训练的多模态图像生成模型
Gitee 官方博客
·


GLM-4.6V开源:从看懂图片到自动完成任务
实时互动网
·