
论文汇总 | 大模型强化学习最新进展,微软/谷歌/斯坦福/人大/小红书等发布信用分配/复杂推理/智能体强化学习重磅成果
内容提要
当前强化学习的发展旨在突破稀疏奖励与静态监督的限制,赋予模型自主学习与自我进化的能力。研究者们提出了ECHO、DelTA和GoLongRL等新方法,以提升智能体在复杂环境中的表现和决策能力。这些研究为构建具备强推理和自学习能力的下一代大模型提供了重要启示。
关键要点
-
当前强化学习的发展旨在突破稀疏奖励与静态监督的限制,赋予模型自主学习与自我进化的能力。
-
强化学习通过感知、决策、执行和反馈的闭环优化行为策略,强调试错学习能力。
-
研究者提出了ECHO、DelTA和GoLongRL等新方法,以提升智能体在复杂环境中的表现和决策能力。
-
ECHO方法通过计算交叉熵预测损失,显著增强了对未见终端动态的预测能力。
-
DelTA方法通过重新加权自归一化目标函数,提升了梯度更新的对比度,超越了现有基线。
-
GoLongRL方案设计了TMN-Reweight机制,优化了多任务混合奖励的处理,提升了模型的泛化能力。
-
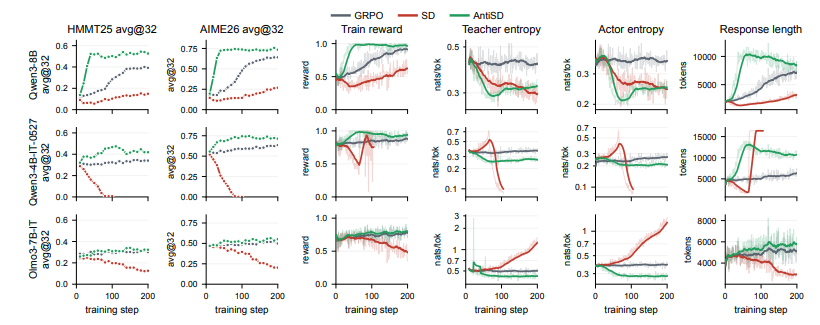
AntiSD方法通过最大化JS散度反转梯度信号,奖励探索性思考,提升了数学推理任务的准确率。
-
RubricEM框架利用评分量表实现细粒度信用分配,提升了长上下文学习的效率。
-
Poly-EPO算法促进了推理生成过程中的多样性探索,提升了策略的扩展潜力。
延伸解读
强化学习的自主学习能力
当前强化学习的研究重点在于突破稀疏奖励和静态监督的限制,赋予模型自主学习的能力。这意味着未来的智能体将能够在复杂环境中通过交互不断优化自身策略,而不仅仅依赖于固定的数据集。这一转变将推动人工智能从被动反应向主动决策的进化。
新方法的实际应用前景
ECHO、DelTA和GoLongRL等新方法的提出,展示了在复杂环境中提升智能体表现的潜力。这些方法不仅提高了模型的预测能力和决策效率,还为多任务处理和长上下文学习提供了新的解决方案,可能在实际应用中显著提升智能体的表现。
风险与挑战
尽管新方法展现出良好的性能,但在实际应用中仍需关注模型的泛化能力和稳定性。特别是在动态环境中,如何确保模型在面对未见数据时依然能够有效学习和决策,是未来研究的重要挑战。
延伸问答
当前强化学习的主要目标是什么?
当前强化学习的主要目标是突破稀疏奖励与静态监督的限制,赋予模型自主学习与自我进化的能力。
ECHO方法如何提升智能体的预测能力?
ECHO方法通过计算交叉熵预测损失,增强了对未见终端动态的预测能力,显著提高了首答准确率。
DelTA方法解决了什么问题?
DelTA方法解决了信用分配粒度过粗的问题,通过重新加权自归一化目标函数,提升了梯度更新的对比度。
GoLongRL方案的创新点是什么?
GoLongRL方案设计了TMN-Reweight机制,优化了多任务混合奖励的处理,提升了模型的泛化能力。
AntiSD方法在数学推理任务中的作用是什么?
AntiSD方法通过奖励探索性思考,提升了数学推理任务的准确率,避免了模型过度依赖已知答案。
RubricEM框架如何实现细粒度信用分配?
RubricEM框架利用评分量表将长轨迹拆分为多个阶段,从而实现细粒度的信用分配。
