
语义缓存与路由:向量分类的两种强大模式
内容提要
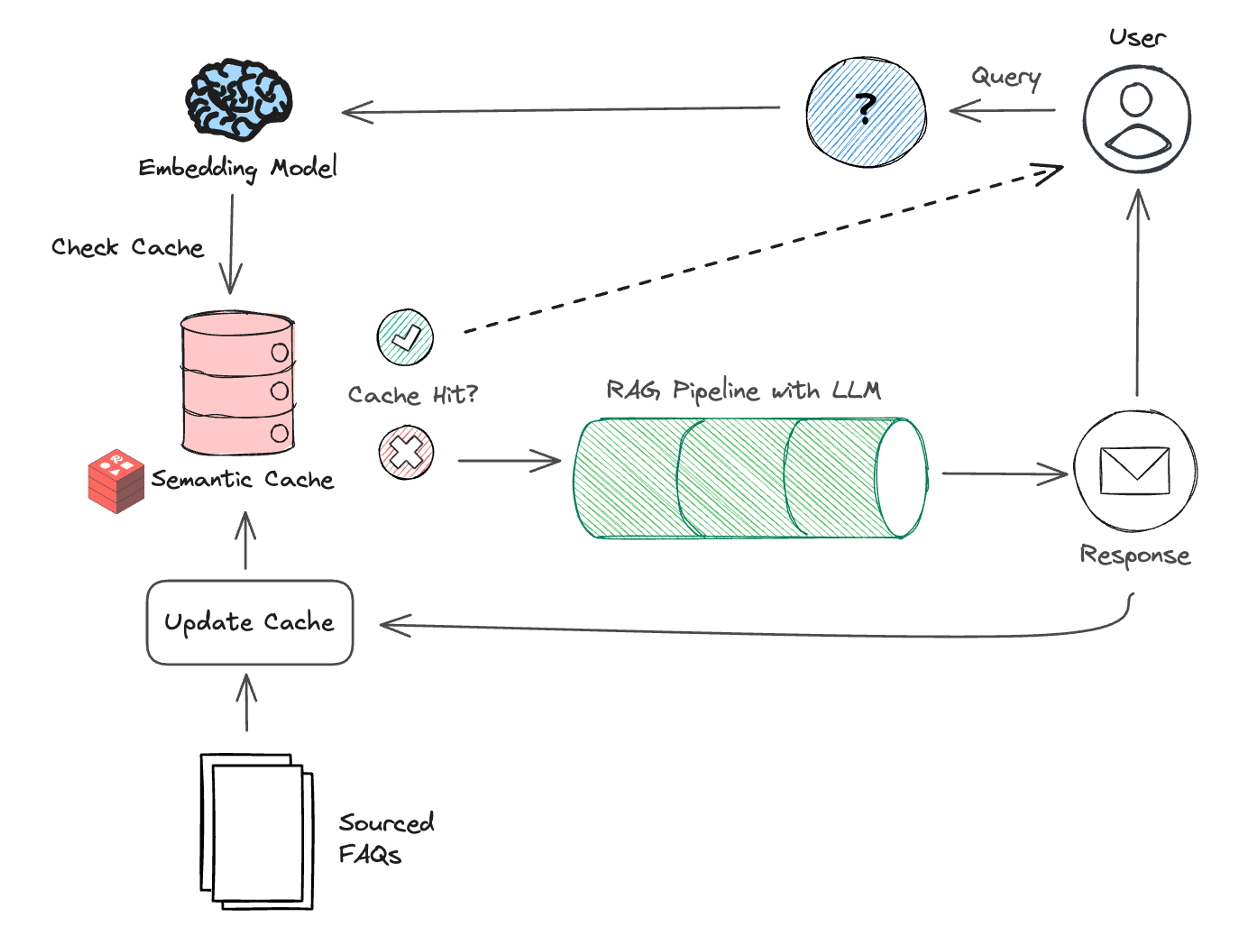
Redis的向量数据类型实现了毫秒级的无监督分类,支持语义缓存和语义路由优化。语义缓存通过向量数学判断缓存命中,语义路由则能快速在多标签中分类输入。这两种模式提升了系统性能,降低了成本,适用于多种应用场景。
关键要点
-
Redis的向量数据类型实现了毫秒级的无监督分类。
-
语义缓存通过向量数学判断缓存命中,提升系统性能。
-
语义路由能够快速在多标签中分类输入,优化系统成本。
-
语义缓存可以在任何流程阶段实现,不仅限于LLM调用前。
-
语义路由扩展了语义缓存的概念,支持在多个潜在标签中进行分类。
-
向量基础分类在Redis中运行毫秒级,不占用显著内存。
-
缓存和路由是通过向量分类实现的不同架构模式。
-
这两种模式可以在应用程序的任何点实现,以提高性能。
延伸解读
语义缓存的优势
语义缓存利用向量数学判断缓存命中,能够在处理重复请求时显著降低延迟和成本。这种方法不仅限于LLM调用前,还可以在其他流程阶段实现,适用于多种应用场景,提升系统整体性能。
语义路由的应用场景
语义路由能够快速将输入分类到多个潜在标签中,适合处理FAQ类问题或需要阻止的敏感话题。通过这种方式,系统可以在低延迟和低成本的情况下,优化响应流程,避免不必要的资源消耗。
向量分类的效率
Redis中的向量基础分类实现毫秒级响应,且内存占用极小。这使得开发者可以在应用程序的任何点实现缓存和路由,提升性能的同时,避免了传统方法的高延迟和高成本问题。
延伸问答
什么是语义缓存,它是如何工作的?
语义缓存通过向量数学判断缓存命中,如果输入向量与缓存输入向量的距离低于设定阈值,则返回之前计算的响应。
语义路由的主要功能是什么?
语义路由能够在多个潜在标签中快速分类输入,帮助系统更有效地响应不同类型的问题。
Redis的向量数据类型有什么优势?
Redis的向量数据类型支持毫秒级的无监督分类,且不占用显著内存,适合高效处理大量数据。
如何在应用程序中实现语义缓存和语义路由?
语义缓存和语义路由可以在应用程序的任何阶段实现,以提高性能,特别是在LLM调用前或其他流程中。
使用语义缓存和路由可以带来哪些好处?
这两种模式可以提升系统性能,降低成本,并优化不同应用场景的响应速度。
语义缓存和传统缓存有什么区别?
传统缓存使用二元操作判断缓存命中,而语义缓存通过向量数学进行更灵活的判断,能够处理相似性。
