
为什么仅靠更便宜的模型无法节省你的人工智能预算
The New Stack
·

动态批处理:实用指南
Redis Blog
·
人工智能中的上下文窗口:为何每个令牌都是预算决策
Redis Blog
·
智能系统中的缓存:内部、分布式和语义
insidejava
·
大语言模型速度基准:指标与基础设施指南
Redis Blog
·
上下文修剪:在不损失质量的情况下减少LLM令牌
Redis Blog
·
我会功夫
Percona Database Performance Blog
·
预填充与解码:大型语言模型推理阶段解析
Redis Blog
·
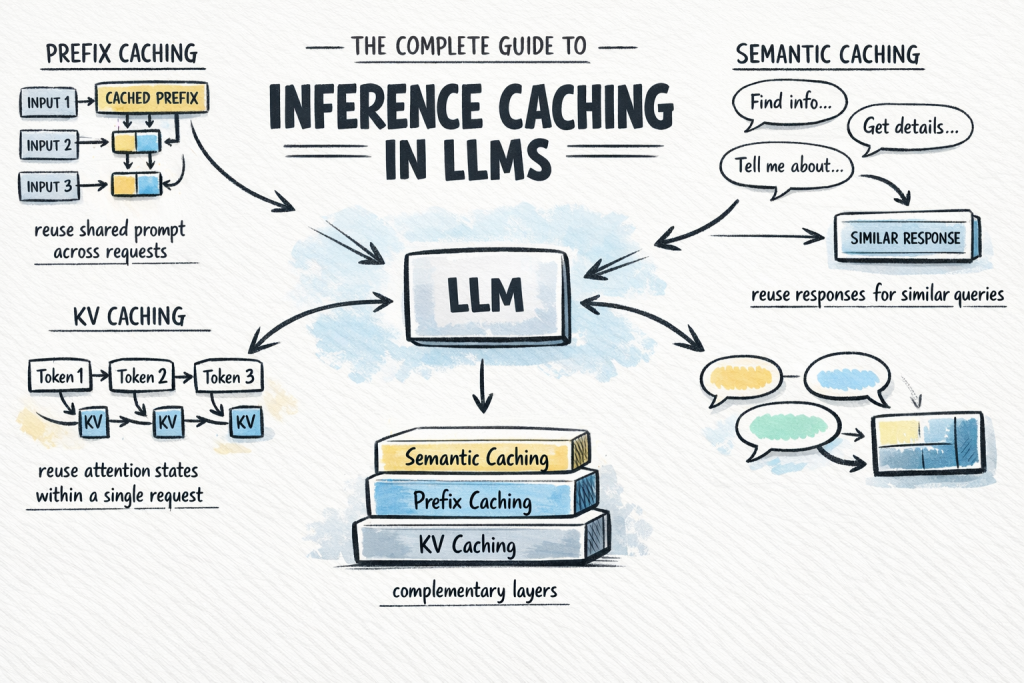
大语言模型推理缓存完整指南
MachineLearningMastery.com
·
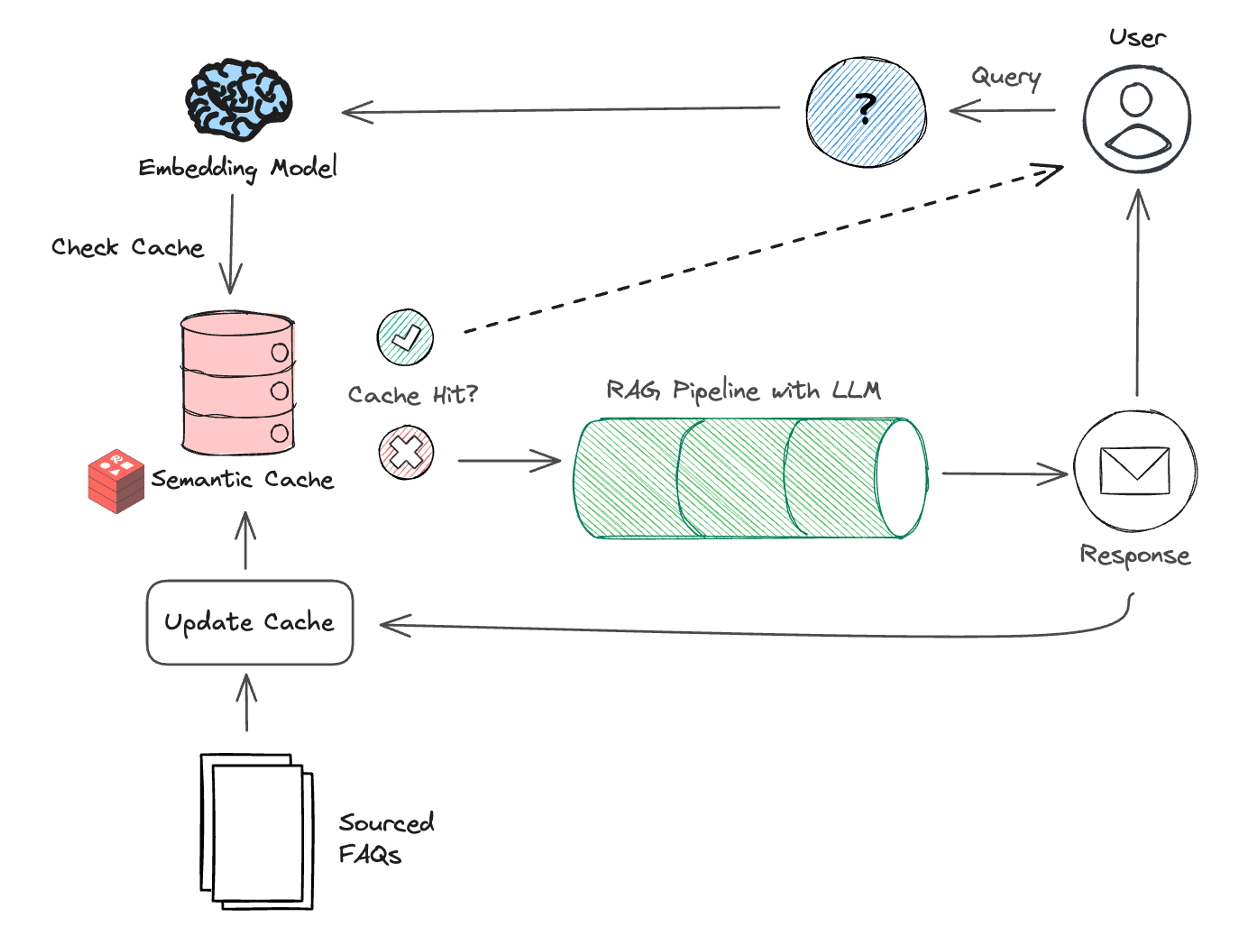
语义缓存与路由:向量分类的两种强大模式
Redis Blog
·

穆罕默德·阿基尔:生产环境中的pg_semantic_cache:标签、驱逐、监控与Python集成
Planet PostgreSQL
·

使用Redis的LLM应用幂等性模式
Redis Blog
·

LLM应用的语义缓存:降低成本40-80%,提升速度250倍
Percona Database Performance Blog
·
你需要的不仅仅是向量数据库
Redis Blog
·

介绍 langcache-embed-v3-small
Redis Blog
·



面向更快、更智能LLM应用的语义缓存
Redis Blog
·
什么是上下文衰退?
Redis Blog
·
