
大语言模型推理缓存完整指南
内容提要
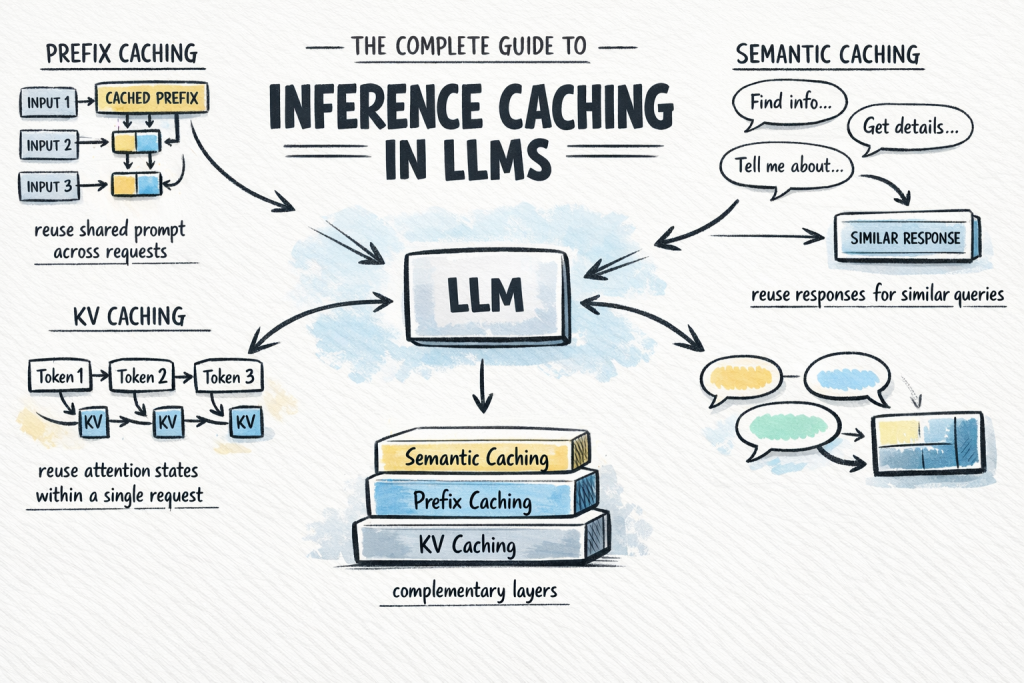
本文介绍了大语言模型中的推理缓存技术,强调其基本概念和重要性。推理缓存通过存储计算结果,减少重复计算,从而降低成本和延迟。主要有三种缓存类型:键值缓存(KV缓存)、前缀缓存和语义缓存。合理选择和组合这些缓存策略,可以显著提升生产系统的效率。
关键要点
-
推理缓存技术通过存储计算结果,减少重复计算,从而降低成本和延迟。
-
主要有三种缓存类型:键值缓存(KV缓存)、前缀缓存和语义缓存。
-
KV缓存在单个推理请求中缓存内部注意状态,避免每个解码步骤重新计算。
-
前缀缓存扩展KV缓存,跨多个请求缓存共享的前缀,提升效率。
-
语义缓存根据语义相似性存储完整的输入/输出对,避免不必要的模型调用。
-
选择合适的缓存策略可以显著提升生产系统的效率,尤其是高查询量的应用场景。
延伸解读
推理缓存的必要性
在大语言模型的应用中,推理缓存技术显得尤为重要。通过存储计算结果,推理缓存能够显著降低重复计算带来的成本和延迟,尤其是在高查询量的场景中。理解推理缓存的工作原理,有助于开发者优化系统性能,提升用户体验。
缓存策略的选择
本文提到的三种缓存类型各有特点,KV缓存是基础,前缀缓存适用于共享长系统提示的场景,而语义缓存则在高查询量的情况下更为有效。开发者应根据具体应用场景,合理选择和组合这些缓存策略,以实现最佳的性能提升。
前缀缓存的结构要求
前缀缓存的有效性依赖于请求中共享部分的完全一致性。任何微小的变化都可能导致缓存失效,因此在设计提示时,应将静态内容放在前面,动态内容放在后面。这一结构要求对提高缓存命中率至关重要。
延伸问答
推理缓存的基本概念是什么?
推理缓存是通过存储计算结果来减少重复计算,从而降低成本和延迟的技术。
推理缓存有哪些主要类型?
推理缓存主要有三种类型:键值缓存(KV缓存)、前缀缓存和语义缓存。
KV缓存是如何工作的?
KV缓存在单个推理请求中缓存内部注意状态,避免每个解码步骤重新计算。
前缀缓存与KV缓存有什么不同?
前缀缓存扩展KV缓存,跨多个请求缓存共享的前缀,而KV缓存仅在单个请求中工作。
语义缓存的优势是什么?
语义缓存根据语义相似性存储完整的输入/输出对,避免不必要的模型调用,提升效率。
如何选择合适的缓存策略?
选择缓存策略时,应考虑应用场景的查询量和相似性,通常先启用前缀缓存,再根据需要添加语义缓存。
