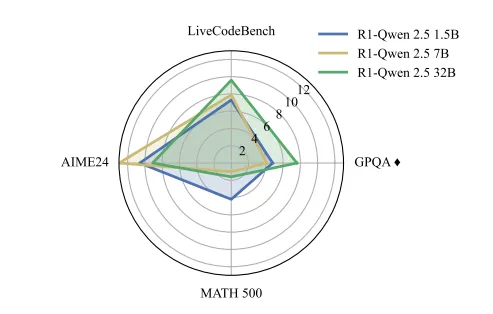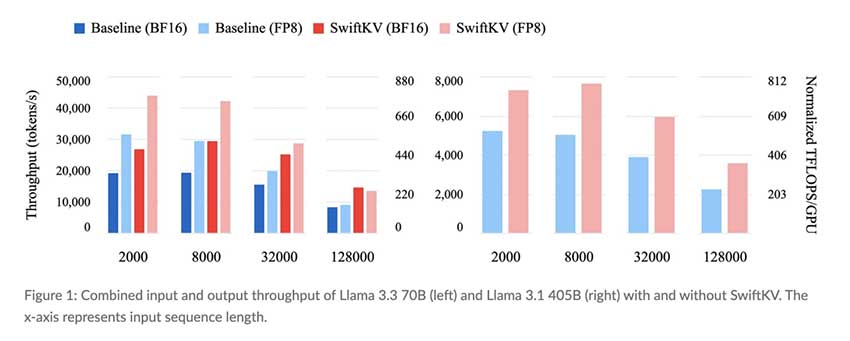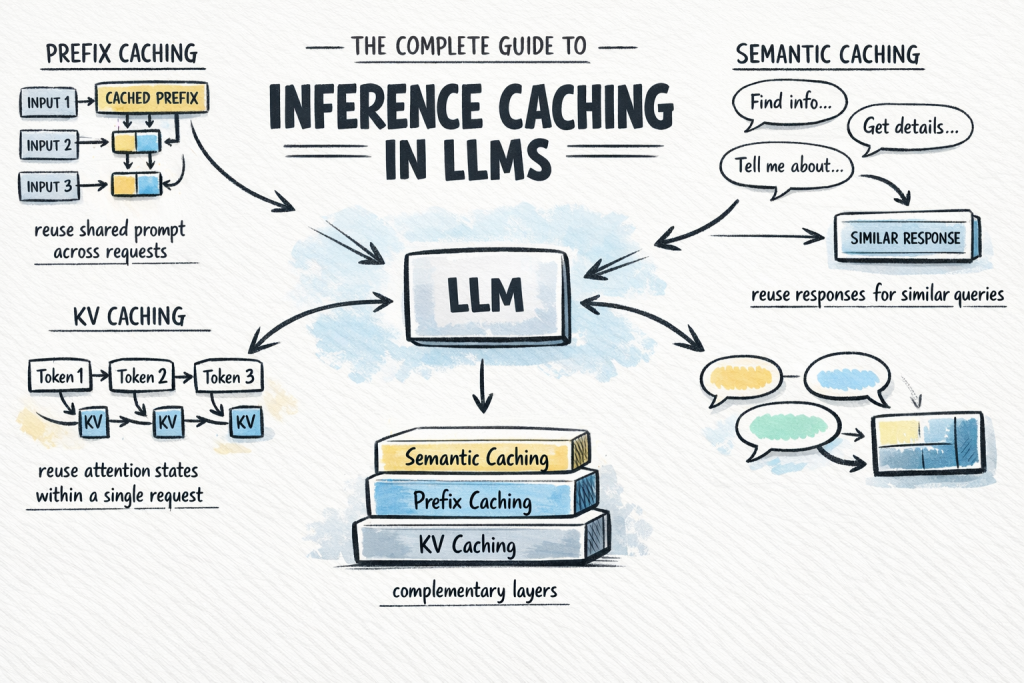
大语言模型推理缓存完整指南
MachineLearningMastery.com
·

通过强化学习优化键值缓存的驱逐策略
Apple Machine Learning Research
·

nanovllm-block_manager
plus studio
·