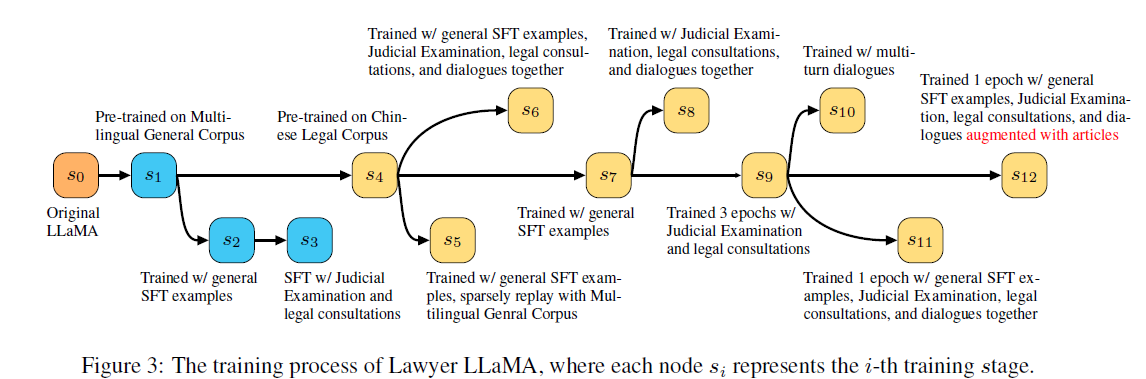
训练中文垂类大模型:Lawyer LLaMA
原文中文,约3500字,阅读约需9分钟。发表于:。开源的通用能力大模型越来越多,但真正有用和落地的是在某个领域专精的垂类模型。初看上去,似乎大模型仅需要少量prompt工作就可以很好地在垂类工作,可事实并非如此。不进行领域微调的通用模型可以很快地构建80分的应用,可是大部分的实用场景,需要95甚至98分的模型效果。这也是为什么在各个领域(如金融、车载、虚拟人)大家都在训练或微调自己大模型的原因。 微调这件事看上去不难,但却有很多未解问题: ...
开源的通用能力大模型越来越多,但真正有用和落地的是在某个领域专精的垂类模型。本文介绍了Lawyer LLaMA训练中文垂类模型的思路,包括预训练、注入法律领域知识、学习推理能力和检索相关法条。实验结果显示,该方案微调垂类模型是可行的。