
通过预训练的生成音频编码器和声码器实现高效且适应性强的语音增强
内容提要
小米的MiLM Plus提出了一种轻量级的语音增强方法,利用预训练音频模型提取特征,通过音频编码器和降噪编码器生成清晰语音,性能优于传统模型,计算效率高。实验结果显示,该系统在语音质量和说话人保真度上具有显著优势。
关键要点
-
小米的MiLM Plus提出了一种轻量级的语音增强方法,利用预训练音频模型提取特征。
-
该方法通过音频编码器和降噪编码器生成清晰语音,性能优于传统模型,计算效率高。
-
实验结果显示,该系统在语音质量和说话人保真度上具有显著优势。
-
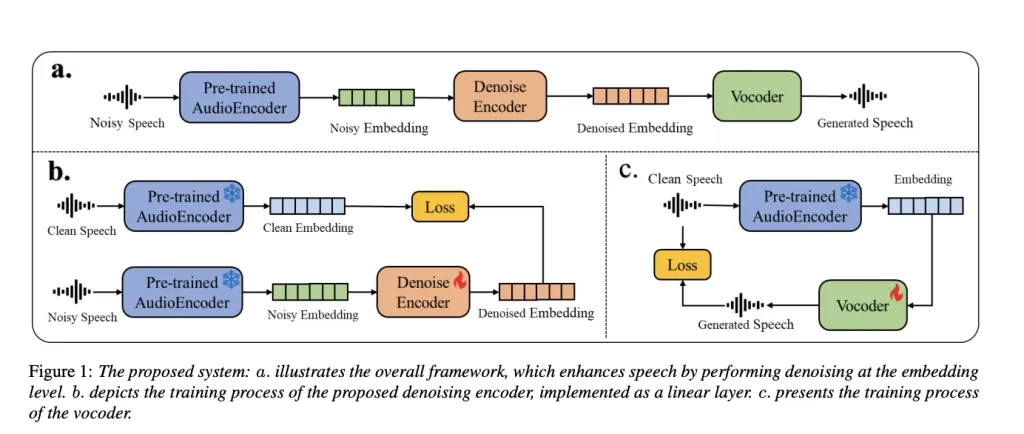
该语音增强系统分为三个主要部分:音频编码器、降噪编码器和声码器。
-
降噪编码器使用均方误差损失函数,最小化带噪嵌入和清晰嵌入之间的差异。
-
声码器通过预测傅里叶谱系数来学习从音频嵌入中重建语音波形。
-
评估结果表明,生成式音频编码器的性能优于判别式编码器。
-
主观听力测试显示,该方法提供了更佳的感知清晰度,凸显了其有效性和多功能性。
延伸解读
语音增强技术的演变
近年来,语音增强技术逐渐从传统的掩码和信号预测方法转向使用预训练音频模型。这种转变使得特征提取更加丰富和可迁移,提升了语音增强的整体性能。小米的MiLM Plus正是这一趋势的代表,利用预训练模型实现了更高效的语音处理。
系统结构与功能
MiLM Plus的语音增强系统由音频编码器、降噪编码器和声码器三部分组成。音频编码器负责提取带噪音频的特征,降噪编码器则对这些特征进行清理,最终声码器将其转换为清晰的语音。这种模块化设计使得系统在不同任务中具有良好的适应性。
性能评估与比较
实验结果显示,MiLM Plus在语音质量和说话人保真度方面显著优于传统的判别式编码器。主观听力测试的平均意见分(MOS)也表明,该系统在感知清晰度上超越了现有的领先模型,显示出其在实际应用中的潜力。
延伸问答
小米的MiLM Plus语音增强方法有什么特点?
小米的MiLM Plus采用轻量级设计,利用预训练音频模型提取特征,通过音频编码器和降噪编码器生成清晰语音,计算效率高,性能优于传统模型。
该语音增强系统的主要组成部分是什么?
该语音增强系统主要由音频编码器、降噪编码器和声码器三部分组成。
降噪编码器是如何工作的?
降噪编码器使用均方误差损失函数,最小化带噪嵌入和清晰嵌入之间的差异,从而清理音频嵌入。
该系统在语音质量方面的表现如何?
实验结果表明,该系统在语音质量和说话人保真度上显著优于传统模型,主观听力测试也显示出更佳的感知清晰度。
生成式音频编码器与判别式编码器的比较结果如何?
评估结果显示,生成式音频编码器在语音质量和说话人保真度方面始终优于判别式编码器。
MiLM Plus的计算效率如何?
MiLM Plus实现了高计算效率,能够在保持高性能的同时,使用较少的参数进行语音增强。
