

语音增强中的自监督学习:从无配对训练到基础模型先验
实时互动网
·

我在Sonos音响上更改了3个设置,瞬间提升了音频表现
ZDNET
·
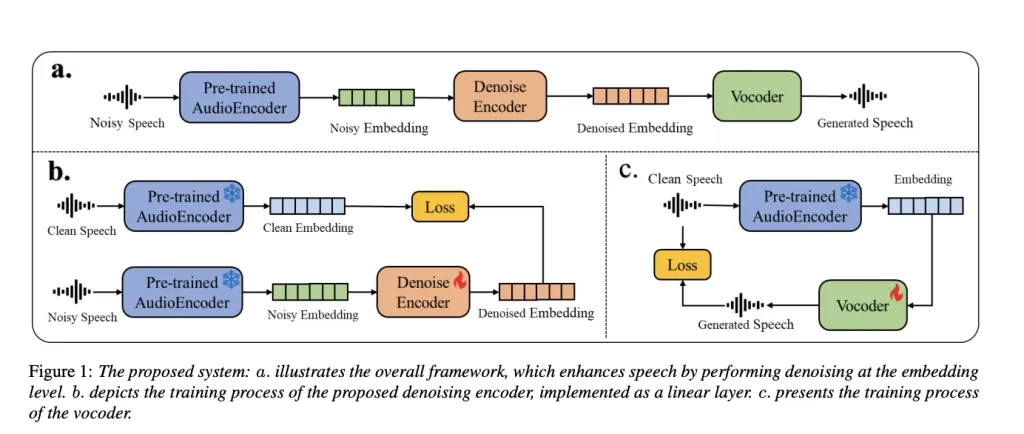
通过预训练的生成音频编码器和声码器实现高效且适应性强的语音增强
实时互动网
·


AI驱动的麦克风阵列使嘈杂环境中的语音清晰度提高40%
DEV Community
·
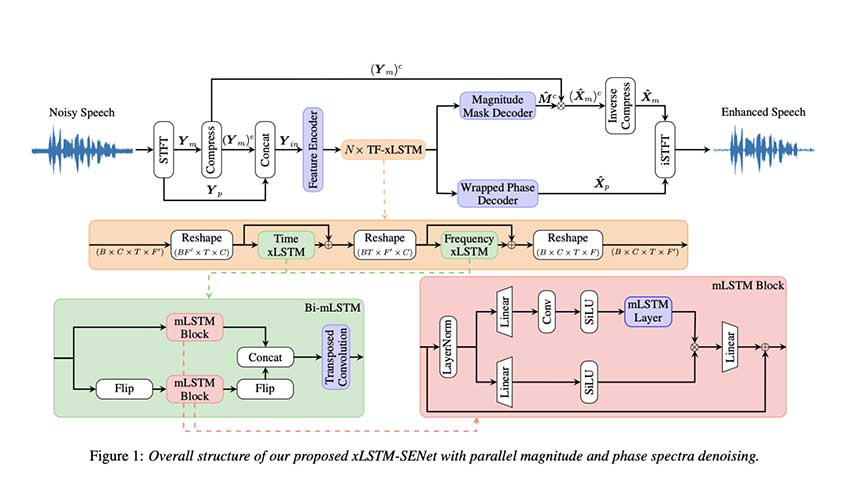
xLSTM-SENet:重新定义单通道语音增强
实时互动网
·
