
《GPT 图解》笔记:Seq2Seq及点积注意力
内容提要
本文介绍了Seq2Seq模型及其点积注意力机制。Seq2Seq用于机器翻译,通过编码器将输入序列转换为上下文表示,解码器生成输出序列。点积注意力计算输入矩阵的相似度,帮助解码器关注输入序列中的重要部分,从而提高上下文捕捉能力,增强翻译效果。
关键要点
-
Seq2Seq模型用于机器翻译,通过编码器将输入序列转换为上下文表示,解码器生成输出序列。
-
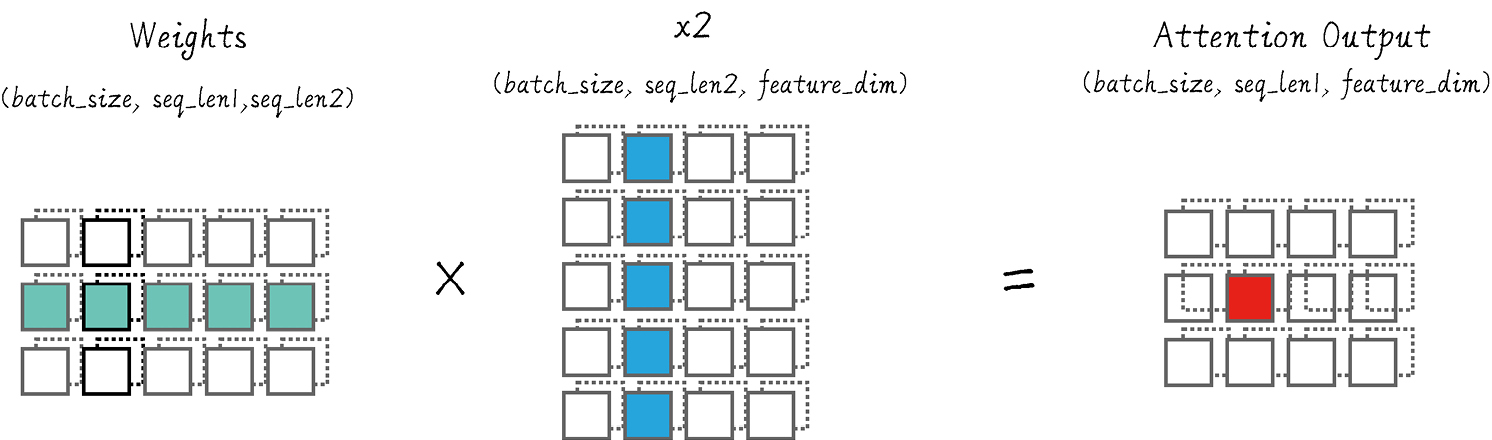
点积注意力机制计算输入矩阵的相似度,帮助解码器关注输入序列中的重要部分。
-
Seq2Seq结构由编码器和解码器组成,编码器生成上下文表示,解码器根据该表示生成输出。
-
带点积注意力的Seq2Seq模型能够动态关注输入序列不同位置的信息,增强上下文捕捉能力。
-
点积注意力通过计算相似度矩阵和加权求和,生成新的上下文表示,提升翻译效果。
延伸解读
Seq2Seq模型的优势
Seq2Seq模型通过编码器和解码器的结构,能够有效处理机器翻译中的序列到序列任务。与传统的RNN模型相比,Seq2Seq不仅关注当前输入,还能利用整个输入序列的信息,从而生成更准确的翻译结果。这种结构特别适合处理长文本和复杂句子,提升了翻译的流畅度和准确性。
点积注意力的作用
点积注意力机制通过计算输入序列中各个token之间的相似度,帮助解码器动态关注输入的重要部分。这种机制使得模型能够在生成输出时,灵活地选择与当前上下文最相关的信息,从而提高翻译的质量和上下文理解能力。
模型训练的注意事项
在训练Seq2Seq模型时,使用Teacher Forcing策略可以加速收敛并提高模型的稳定性。需要注意的是,训练数据的准备和损失函数的选择对模型性能有重要影响。此外,模型的复杂性可能导致过拟合,因此适当的正则化和验证集的使用是必要的。
延伸问答
Seq2Seq模型的主要功能是什么?
Seq2Seq模型用于机器翻译,通过编码器将输入序列转换为上下文表示,解码器生成输出序列。
点积注意力机制是如何工作的?
点积注意力机制通过计算输入矩阵的相似度,帮助解码器关注输入序列中的重要部分,从而生成新的上下文表示。
Seq2Seq模型中编码器和解码器的作用是什么?
编码器将输入序列编码为上下文表示,解码器根据该表示生成输出序列。
带点积注意力的Seq2Seq模型相比于传统Seq2Seq有什么优势?
带点积注意力的Seq2Seq模型能够动态关注输入序列不同位置的信息,增强上下文捕捉能力,提升翻译效果。
如何训练Seq2Seq模型?
训练Seq2Seq模型需要创建训练数据,初始化隐藏状态,使用损失函数计算损失,并通过反向传播更新模型参数。
点积注意力如何计算相似度矩阵?
点积注意力通过计算输入矩阵的点积,生成相似度矩阵,并对其进行softmax处理以得到注意力权重。
