


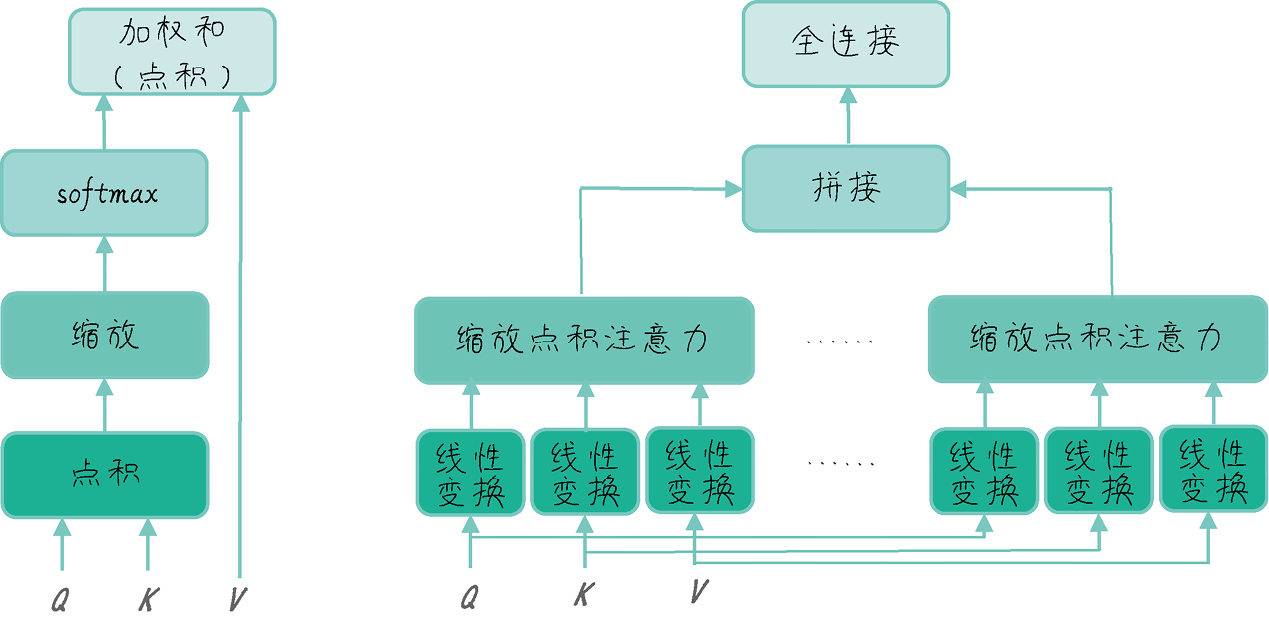
《GPT 图解》笔记:Transformer
Ying’s Blog
·
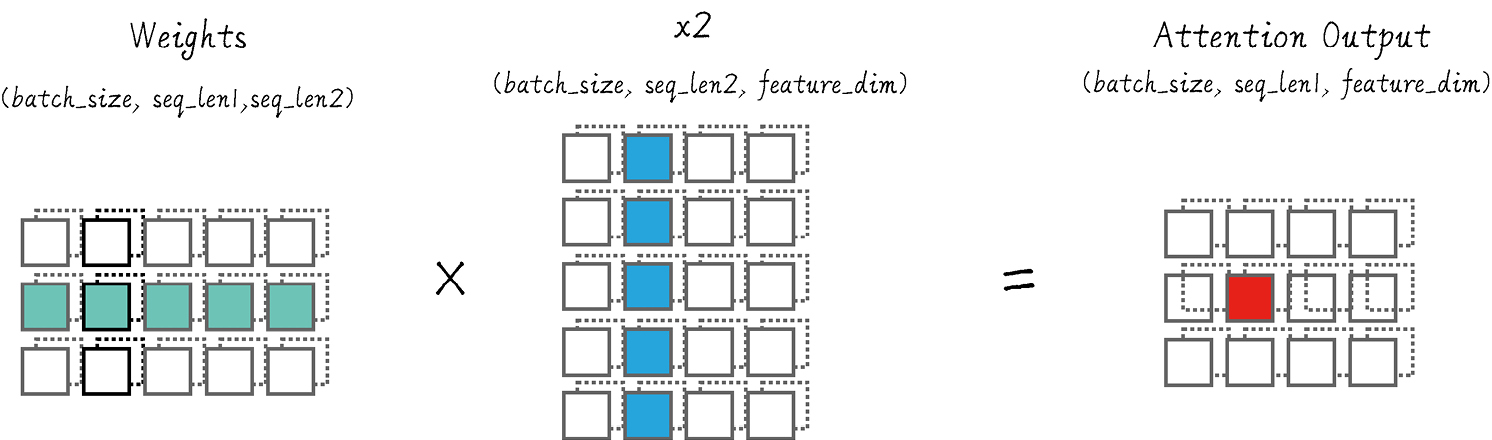
《GPT 图解》笔记:Seq2Seq及点积注意力
Ying’s Blog
·

VideoLAN 发布 Dav2d 开源 AV2 解码器
实时互动网
·

在线教程丨GLM-Image基于自回归+扩散解码器混合架构,精准理解指令写对文字
HyperAI超神经
·
Shotcut 26.1 Beta 视频编辑器新增硬件解码器选项
实时互动网
·

T5Gemma模型再更新,谷歌还在坚持编码器-解码器架构
机器之心
·



AV1解码生态全景图
实时互动网
·

AI 论文周报丨递归推理方法/轻量级解码器架构/深度卷积神经网络架构……多领域前沿动态一览
HyperAI超神经
·

Ateme 推出 DR5000e Kyrion 解码器
实时互动网
·
