
《GPT 图解》笔记:Transformer
内容提要
这篇文章介绍了Transformer模型的结构和关键概念。Transformer通过注意力机制替代RNN,解决了序列建模中的上下文依赖问题。引入位置编码使模型能够感知token的位置信息,注意力机制包括自注意力和交叉注意力。编码器和解码器结构相似,但解码器使用因果掩码以确保生成序列的自回归特性。整体上,Transformer实现了高效的并行计算和长距离依赖处理。
关键要点
-
Transformer模型使用注意力机制替代RNN,解决了序列建模中的上下文依赖问题。
-
引入位置编码,使模型能够感知token的位置信息,正弦位置编码便于学习相对位置关系。
-
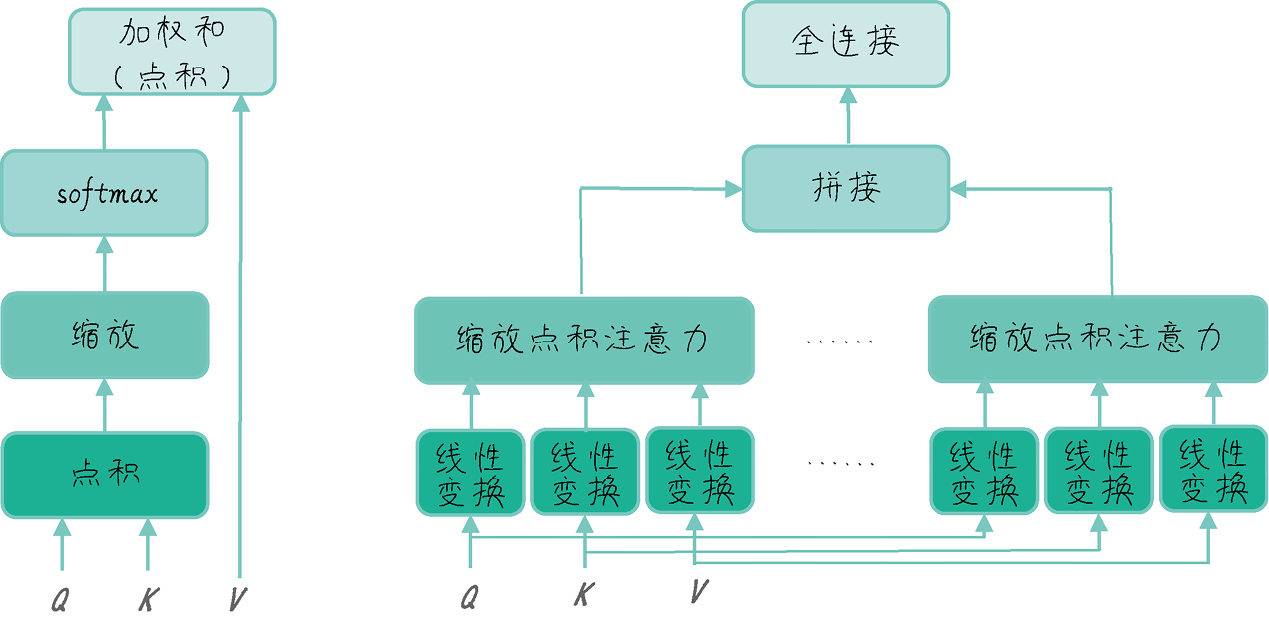
注意力机制包括自注意力和交叉注意力,自注意力的Q、K、V来自同一输入,交叉注意力的Q来自解码器,K和V来自编码器。
-
编码器由多个相同结构的层堆叠而成,采用双向自注意力,能够看到整个输入序列。
-
解码器采用自回归生成方式,使用填充掩码和因果掩码,确保每个位置只能看到当前位置及之前的位置。
-
Transformer的整体架构结合了编码器和解码器,能够实现高效的并行计算和长距离依赖处理。
延伸解读
Transformer的优势
Transformer模型通过注意力机制取代了传统的RNN,显著提高了序列建模的效率。它能够并行处理数据,解决了长距离依赖问题,使得在处理大规模数据时表现更为优越。尤其在自然语言处理领域,Transformer的应用使得模型能够更好地理解上下文关系,提升了生成文本的质量。
位置编码的重要性
位置编码在Transformer中扮演着关键角色,它为模型提供了token的位置信息。由于Transformer的自注意力机制无法自然地处理序列顺序,位置编码的引入使得模型能够学习到相对位置关系,从而在生成和理解文本时保持上下文的连贯性。这一设计使得模型在面对不同长度的输入时,依然能够有效泛化。
注意力机制的多样性
Transformer中的注意力机制分为自注意力和交叉注意力,前者用于处理输入序列内部的关系,后者则结合了编码器的输出信息。这种设计使得解码器在生成每个token时,能够同时考虑到历史上下文和源序列的信息,从而提升了生成的准确性和流畅性。
延伸问答
Transformer模型的主要创新是什么?
Transformer模型通过注意力机制替代了RNN,解决了序列建模中的上下文依赖问题,实现了并行计算。
位置编码在Transformer中有什么作用?
位置编码使模型能够感知token的位置信息,弥补了自注意力机制缺乏顺序感知能力的问题。
Transformer的编码器和解码器有什么区别?
编码器采用双向自注意力,能够看到整个输入序列,而解码器使用自回归生成方式,只能看到当前位置及之前的位置。
自注意力和交叉注意力的区别是什么?
自注意力的Q、K、V来自同一输入,而交叉注意力的Q来自解码器,K和V来自编码器。
Transformer如何处理长距离依赖问题?
Transformer通过注意力机制允许每个token根据需要动态聚合其它token的信息,从而更好地处理长距离依赖。
Transformer模型的并行计算优势是什么?
由于不依赖于RNN的递归状态传递,Transformer能够实现高效的并行计算,提升训练速度。
