

基于长音频编码的分段注意力解码
Apple Machine Learning Research
·
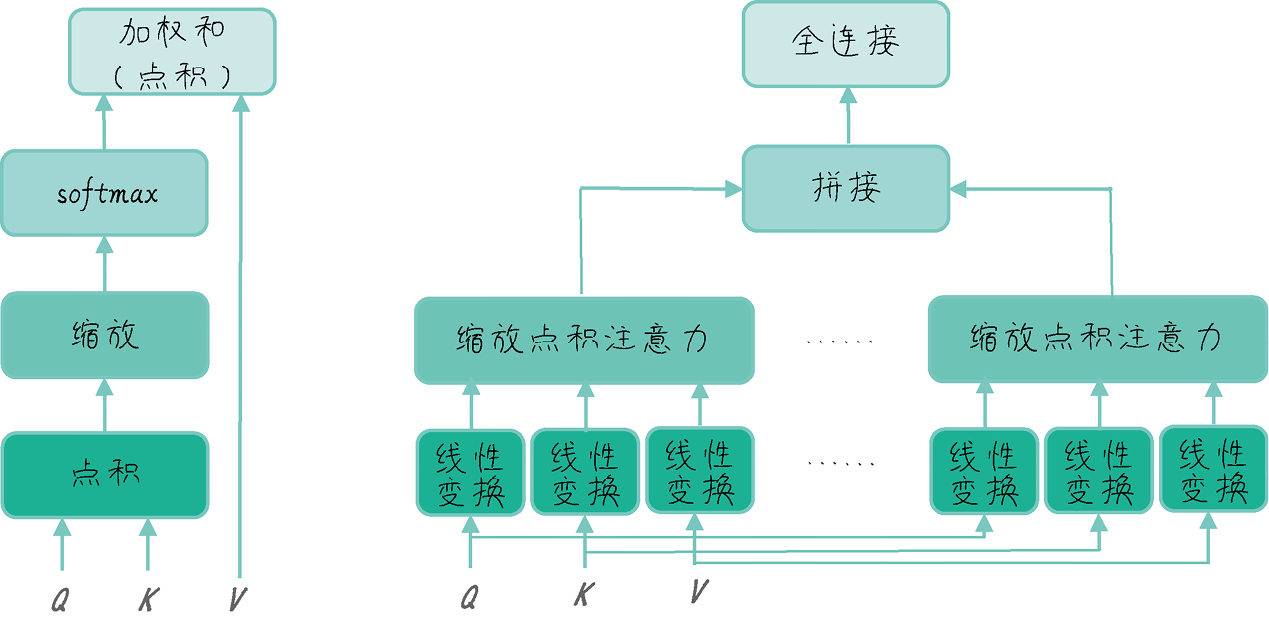
《GPT 图解》笔记:Transformer
Ying’s Blog
·

学习大型语言模型中变压器架构的演变
freeCodeCamp.org
·

位置编码中的插值及YaRN在更大上下文窗口中的应用
MachineLearningMastery.com
·

变换器模型中的位置编码
MachineLearningMastery.com
·

解读人工智能术语:开发者理解基础知识指南
DEV Community
·



