

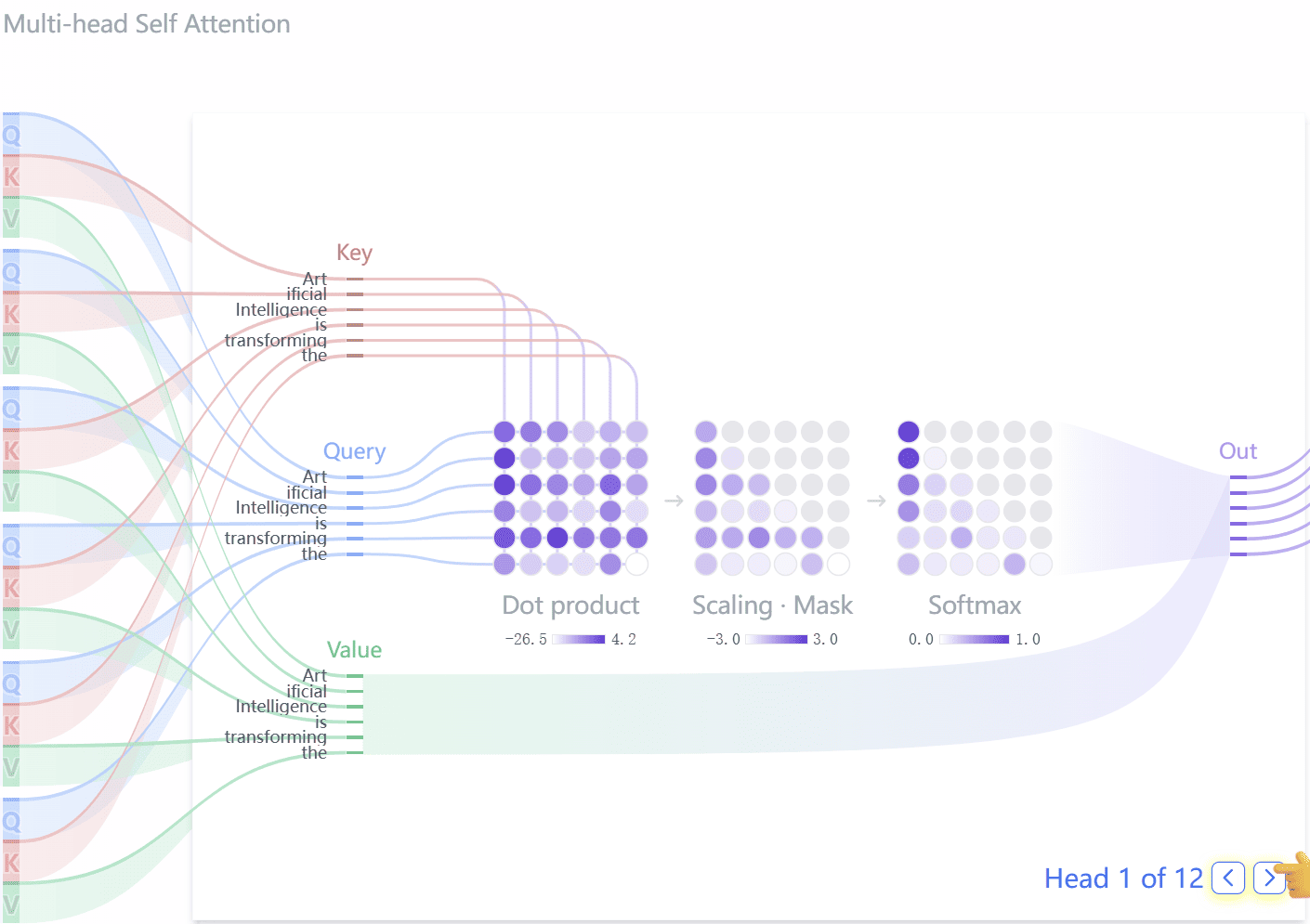
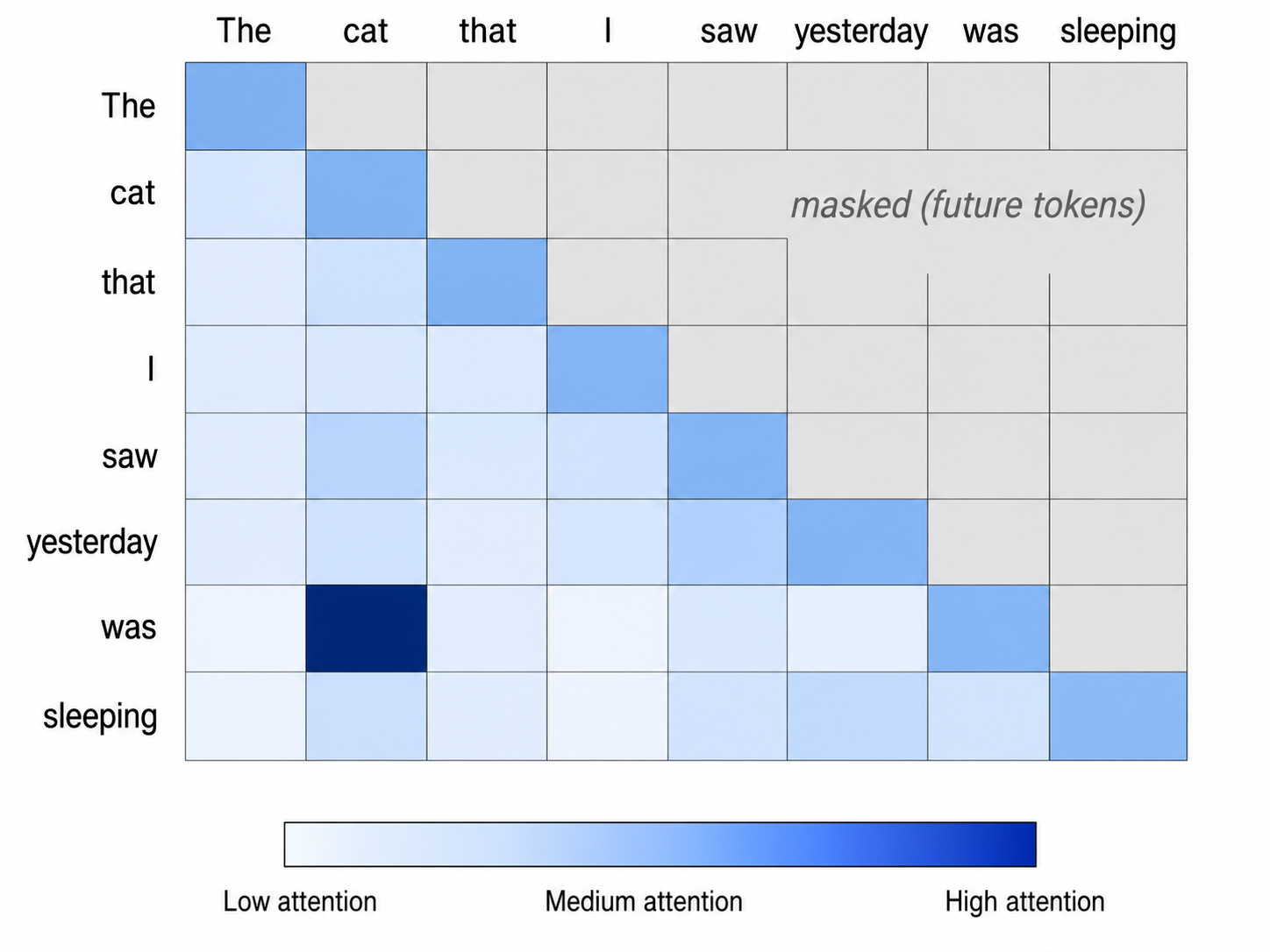
LLM 究竟是如何工作的?
鸟窝
·
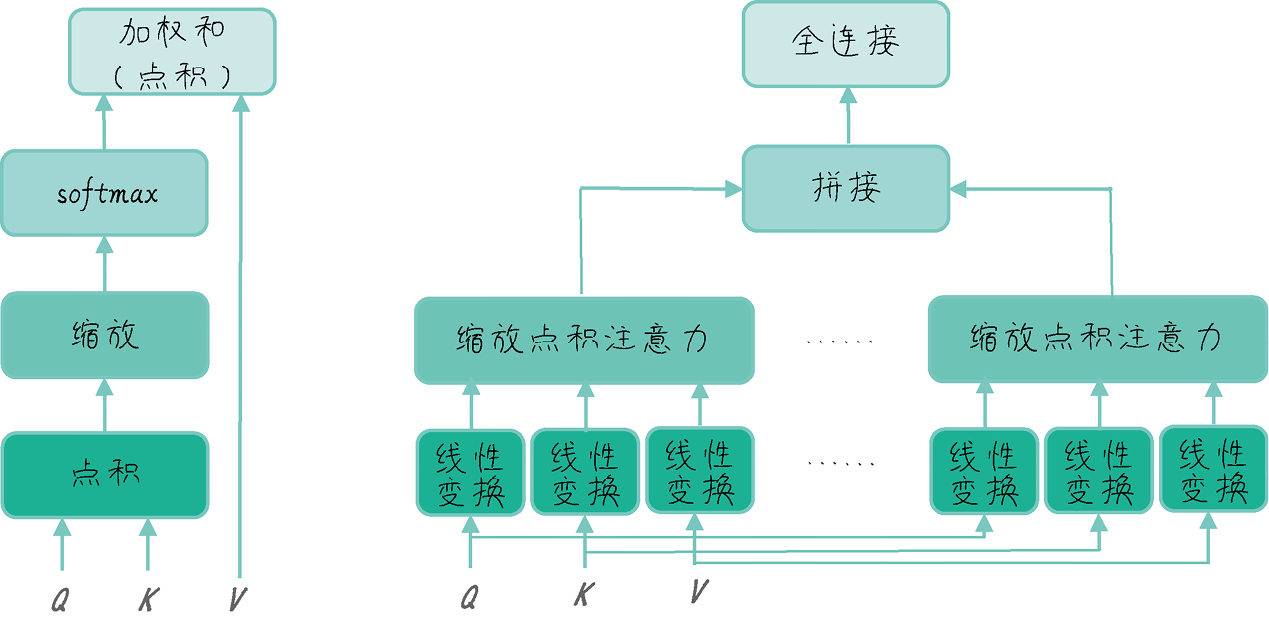
《GPT 图解》笔记:Transformer
Ying’s Blog
·
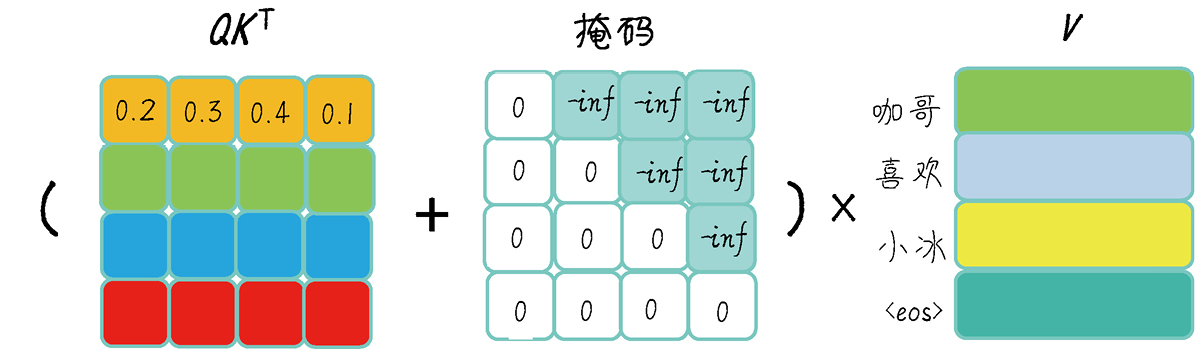
《GPT 图解》笔记:QKV、多头注意力及掩码
Ying’s Blog
·

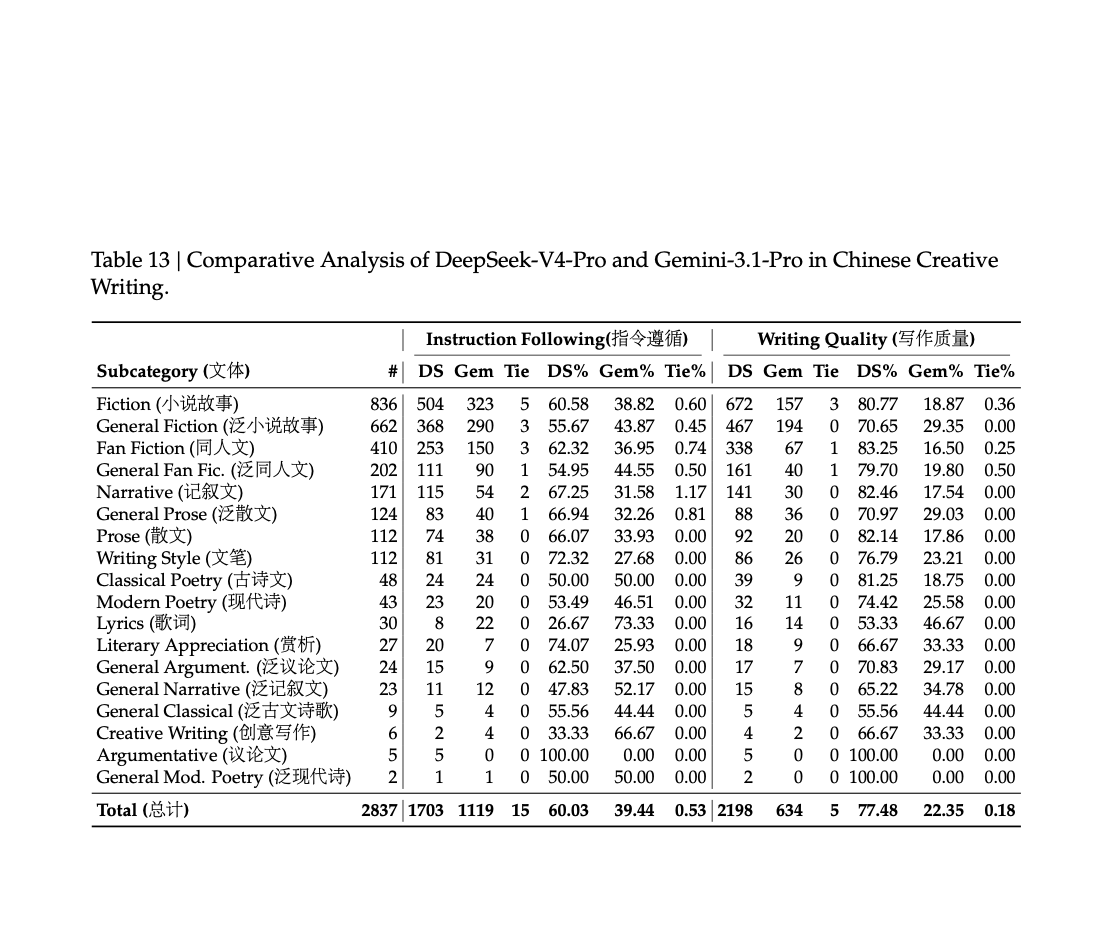
大模型架构的下半场
量子位
·
