
从递归神经网络到变换器
内容提要
自然语言处理经历了巨大的演变,传统的序列到序列模型依赖递归神经网络(RNN),但在处理长序列时存在信息瓶颈。为了解决这一问题,引入了注意力机制,使解码器能够动态关注输入序列的不同部分。现代的Transformer模型通过堆叠注意力层,能够高效处理复杂的序列数据,广泛应用于文本生成和图像处理等领域。
关键要点
-
自然语言处理经历了巨大的演变,传统的序列到序列模型依赖递归神经网络(RNN)。
-
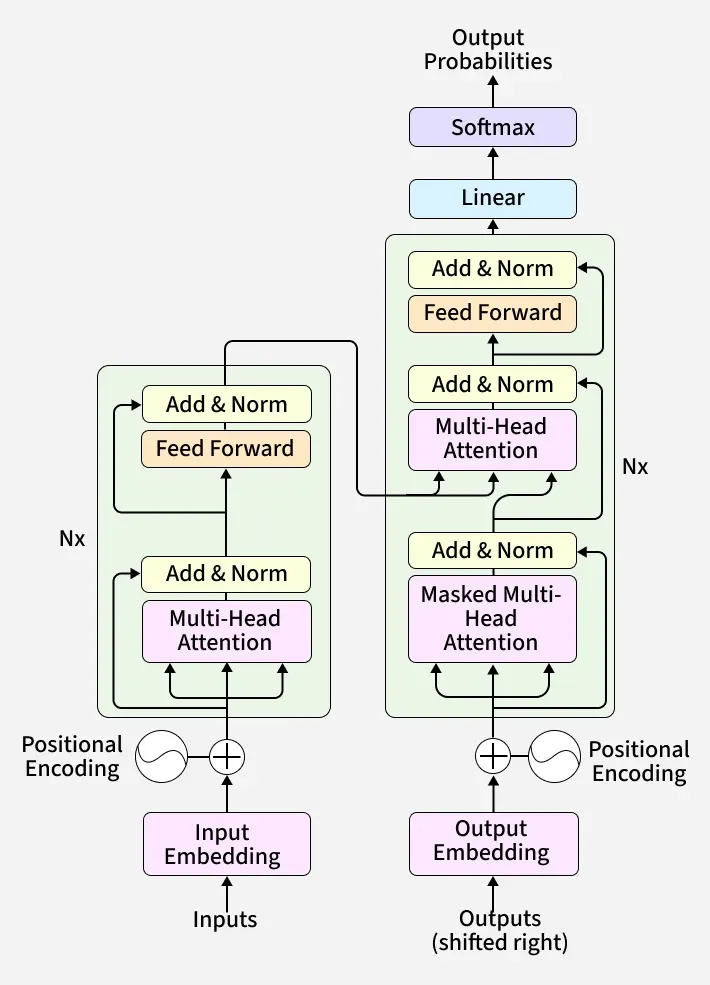
传统的Seq2Seq模型由编码器RNN和解码器RNN组成,编码器处理输入序列并生成隐藏状态,解码器逐步生成输出序列。
-
在处理长输入序列时,固定大小的上下文向量难以捕捉所有相关细节,导致信息丢失。
-
为了解决上下文瓶颈,引入了注意力机制,使解码器能够动态关注输入序列的不同部分。
-
注意力机制的关键优势包括动态聚焦、无固定瓶颈和完全可微分性。
-
现代Transformer模型通过堆叠注意力层,能够高效处理复杂的序列数据,广泛应用于文本生成和图像处理等领域。
-
Transformer模型的架构允许并行处理,显著提高了计算效率。
-
现代Transformer模型在架构上进行了多项改进,如预归一化、RMSNorm和SwiGLU激活函数,以提高训练稳定性和性能。
-
混合专家(MoE)架构通过稀疏激活技术,允许模型在不显著增加计算成本的情况下扩展参数数量。
延伸解读
注意力机制的优势
注意力机制的引入解决了传统RNN模型在处理长序列时的信息瓶颈问题。通过动态关注输入序列的不同部分,模型能够更有效地捕捉上下文信息,从而提高生成文本的质量。这种灵活性使得模型在面对复杂任务时表现更佳,尤其是在机器翻译和文本生成等领域。
Transformer的并行处理能力
与传统的递归神经网络不同,Transformer模型的架构允许并行处理,这显著提高了计算效率。这一特性使得Transformer在处理大规模数据时更具优势,尤其是在训练大型语言模型时,能够大幅缩短训练时间,提升模型的实用性。
现代Transformer的架构改进
现代Transformer模型在架构上进行了多项改进,如预归一化和RMSNorm,这些改进不仅提高了训练的稳定性,还使得模型能够更深层次地学习。了解这些技术细节有助于研究人员在实际应用中选择合适的模型架构,以达到最佳性能。
延伸问答
递归神经网络(RNN)在自然语言处理中的作用是什么?
递归神经网络(RNN)用于传统的序列到序列模型,负责处理输入序列并生成隐藏状态,帮助生成输出序列。
注意力机制是如何解决上下文瓶颈问题的?
注意力机制允许解码器在每个解码步骤动态关注输入序列的不同部分,从而避免依赖单一的固定上下文向量,减少信息丢失。
现代Transformer模型相比于传统RNN有什么优势?
现代Transformer模型通过堆叠注意力层实现高效的并行处理,显著提高计算效率,并能处理复杂的序列数据。
Transformer模型的架构有哪些关键改进?
现代Transformer模型引入了预归一化、RMSNorm和SwiGLU激活函数等改进,以提高训练稳定性和性能。
混合专家(MoE)架构的主要优势是什么?
混合专家架构通过稀疏激活技术,允许模型在不显著增加计算成本的情况下扩展参数数量,从而提高模型的能力和效率。
Transformer模型在图像处理中的应用是什么?
Transformer模型可以用于图像处理,通过将图像分割为固定大小的补丁并使用自注意力机制来理解全局上下文。
