

仙剑 DOS 版:移植到 Rust,再用神经网络实时超分
Lv. MAX
·
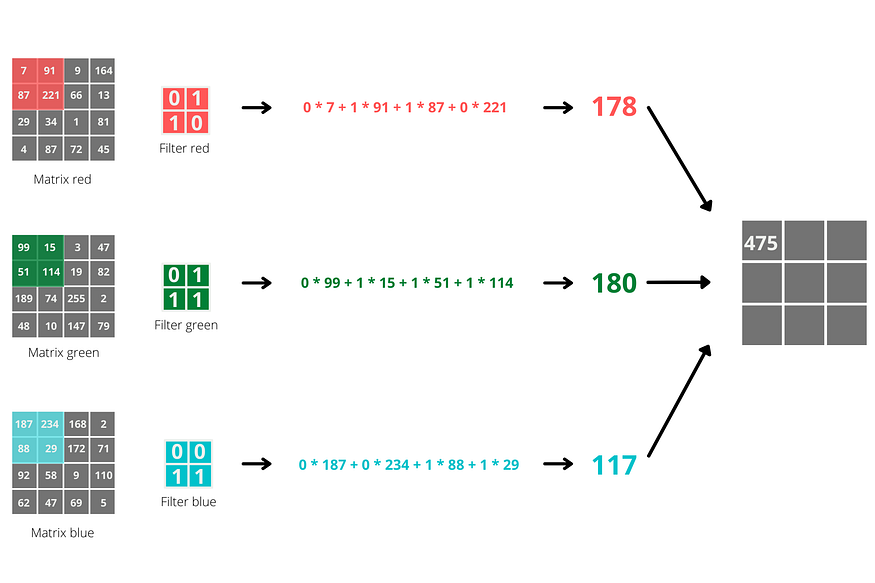
卷积神经网络、递归神经网络与变换器解析:深度学习关键概念的思维模型
freeCodeCamp.org
·

神经网络真的正在收敛为同一个世界模型吗
极道
·
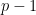
模运算挑战
What's new by TerryTao
·

ParaRNN:大规模非线性递归神经网络,可并行训练
Apple Machine Learning Research
·
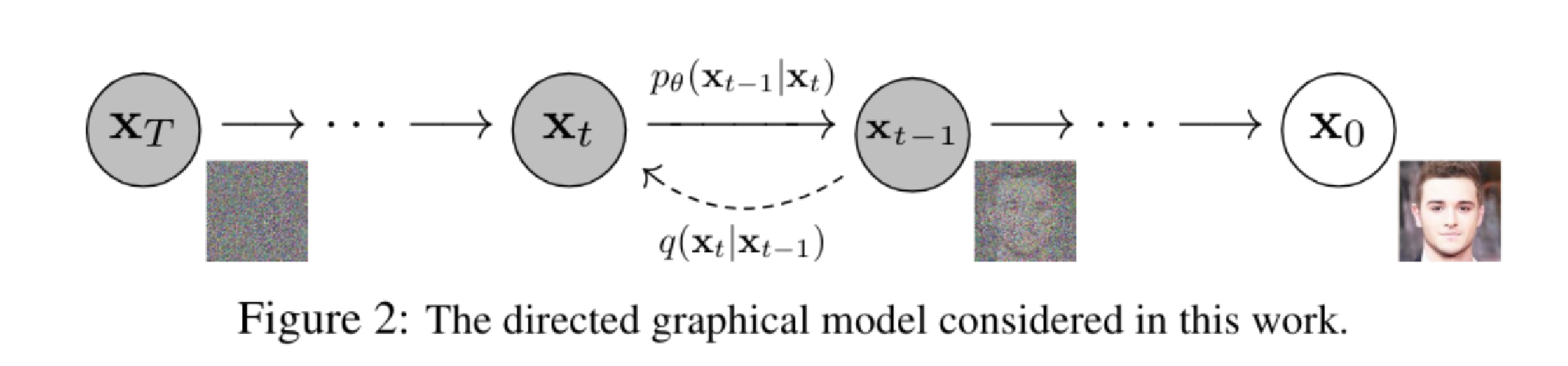
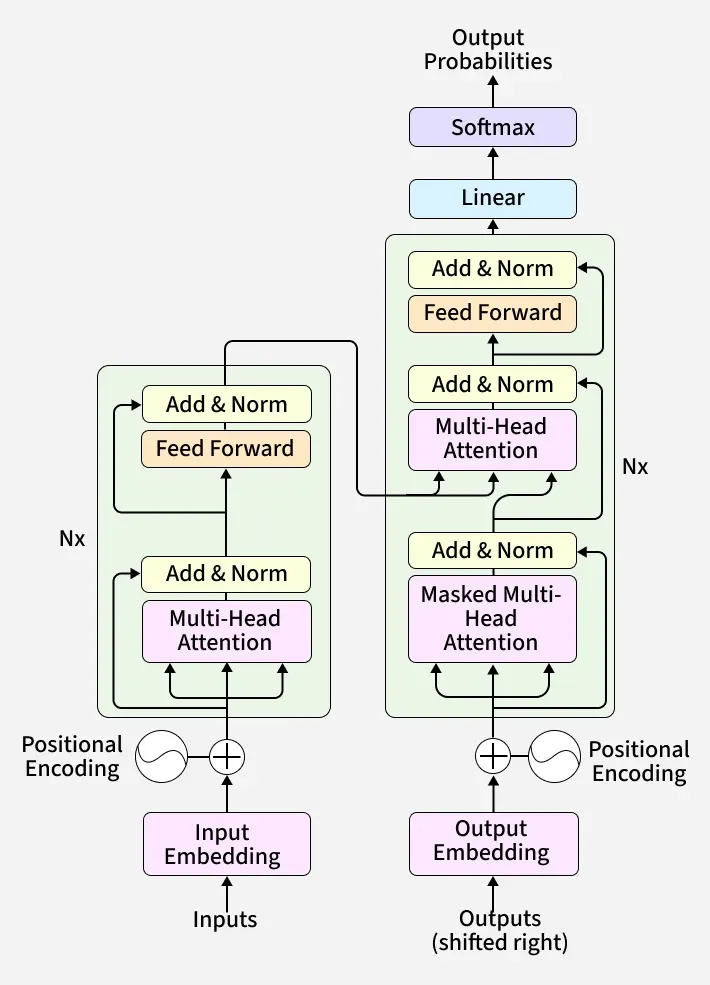

【TVM教程】理解 Relax 抽象层
HyperAI超神经
·

CS231n 讲义 V:卷积神经网络基础
Louis Aeilot's Blog
·
![[实验性] 有开发者破解苹果ANE神经网络引擎 原来M4芯片也能直接训练小模型](https://img.lancdn.com/landian/2026/03/111996.png)

解决简街的“掉落的神经网络”难题
Yi's blog
·
