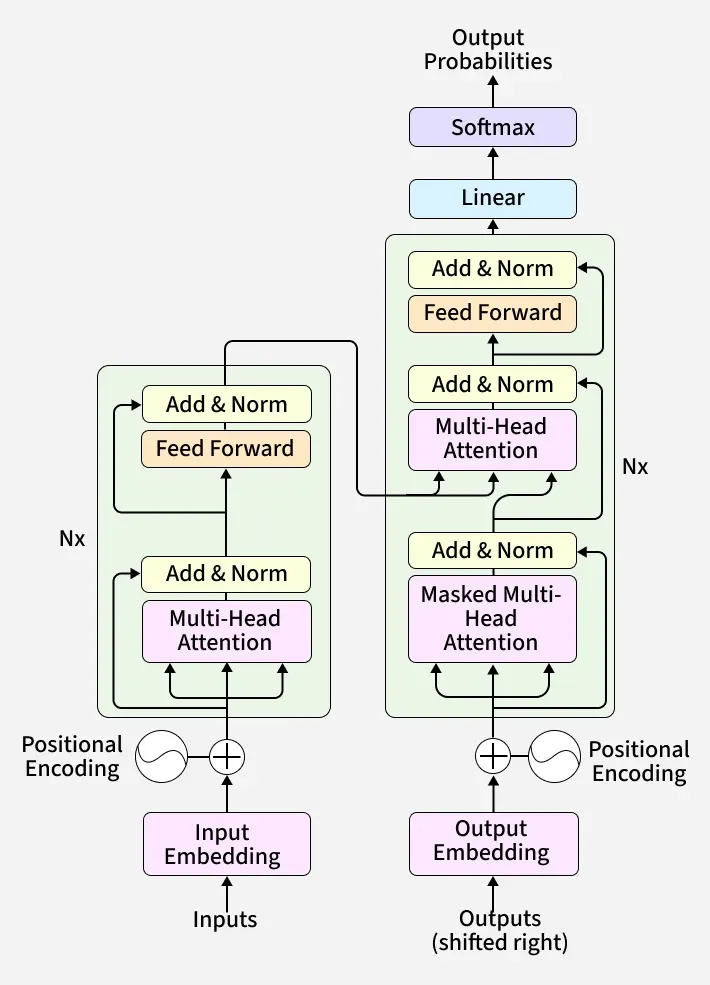
自然语言处理经历了巨大的演变,传统的序列到序列模型依赖递归神经网络(RNN),但在处理长序列时存在信息瓶颈。为了解决这一问题,引入了注意力机制,使解码器能够动态关注输入序列的不同部分。现代的Transformer模型通过堆叠注意力层,能够高效处理复杂的序列数据,广泛应用于文本生成和图像处理等领域。
本研究提出了一种基于ByT5和mT5架构的序列到序列模型,旨在解决卢森堡语文本中的拼写变异问题。该模型通过真实数据训练,显示出在文本规范化方面的优势,展现了在缺乏标准化数据时进行自然语言处理的潜力。
文章讨论了三种序列到序列模型:RNN、LSTM和GRU,比较了它们的特点、应用及各自的优缺点。
本文介绍了多种基于序列到序列模型的关系抽取方法,如seq2rel、RSMAN和PRiSM,展示了它们在生物医学数据集上的优越性能。这些方法通过引入注意力机制、迭代推理和关系嵌入等技术,克服了传统方法的局限性,尤其在低资源环境和长尾问题上表现突出。
本文提出了一个多维度的共情评估框架,旨在测量发言者意图与听众感知之间的共情。研究发现,序列到序列语言模型的分类器在自动对话共情评估中表现最佳。同时,探讨了大型语言模型在生成同理心回应方面的改进方法,强调用户情感检测和多模式输入的重要性。
本文研究了将预训练的语言模型表征集成到序列到序列模型中的不同策略,并将其应用于神经机器翻译和抽象摘要。实验证明,加入编码器网络的预训练表示是最有效的,可以在减慢推理速度仅14%的情况下获得高达5.3 BLEU的增益,并且即使有数百万个句对可用时,仍然可以观察到改进。最后,在CNN/DailyMail的完整文本版本上,达到了最新的研究成果。
本论文研究了唇语识别的两种模型:使用自注意力机制的CTC和序列到序列模型,以及唇语识别与音频识别的互补性。同时,介绍了新的数据集LRS2-BBC,并公开发布。实验结果表明,该模型的表现超过了以前的相关工作。
该研究探讨了对深度学习模型中的序列到序列模型进行对抗攻击的影响。研究发现,机器翻译模型对已知最佳对抗攻击表现出鲁棒性,但在次优方法中,该攻击方法优于其他方法。另外,基于混合单个字符的攻击也是一个有力的候选方法。
本研究提出了一种基于序列到序列模型的 Duration-Flexible 情感语音转换方法,通过引入样式自编码器和单位对齐器,实现了并行语音生成,提高了转换的可靠性和效率。该方法通过跨注意机制将语言和语外信息与各种情感同步,并通过样式自编码器对样式元素进行解耦和操作。经过主客观评估证明了该方法在领域内的优越性。
本论文研究了唇语识别的两种模型:使用自注意力机制的CTC和序列到序列模型。同时,介绍了新的数据集LRS2-BBC,并公开发布。实验结果表明,该模型在有噪音的情况下表现优于以前的相关工作。
本研究使用基于Transformer的序列到序列模型,仅使用850万个参数,在DataVerse Challenge - ITVerse 2023中以0.10582的字错误率获得第一名,实现了汉语中每个单词的国际音标。
本文介绍了序列到序列模型,由编码器和解码器组成,已在机器翻译、文本摘要和图像字幕等任务中成功应用。注意力机制是解决上下文向量瓶颈问题的技术。
本文介绍了一个新的数据集,用于在知识图谱上进行口头回答的对话式问答。通过扩展现有的多轮对话式问答数据集,提供了新的贡献,并使用五个序列到序列模型进行了实验,同时保持语法的正确性。进行了误差分析,详细说明了模型在指定类别中的误差率。提议将答案口头化的数据集公开,并详细说明其使用,以便广泛使用。
本文介绍了LSTM指针生成器和带硬单调注意力的序列到序列模型,用于标准化语素分割。实验结果显示,在低资源情境下,这些新方法的准确度比现有方法高出11.4%。然而,在真正的低资源语言中,最好的模型仅获得了37.4%和28.4%的准确度,标准化分割仍然具有挑战性。
该文介绍了一种结合检索和生成方法的模型,使用关注模块检索相关的用户生成数据评论,并与文章一起作为输入,使用具有复制机制的序列到序列模型。实验证明该模型在大规模评论生成数据集上表现稳健,并在BLEU-1得分方面显著优于其他强基线模型。
完成下面两步后,将自动完成登录并继续当前操作。