

DeepSeek又变强了:发布DSpark框架 推理速度提升超60%
TechWeb 全站精华
·
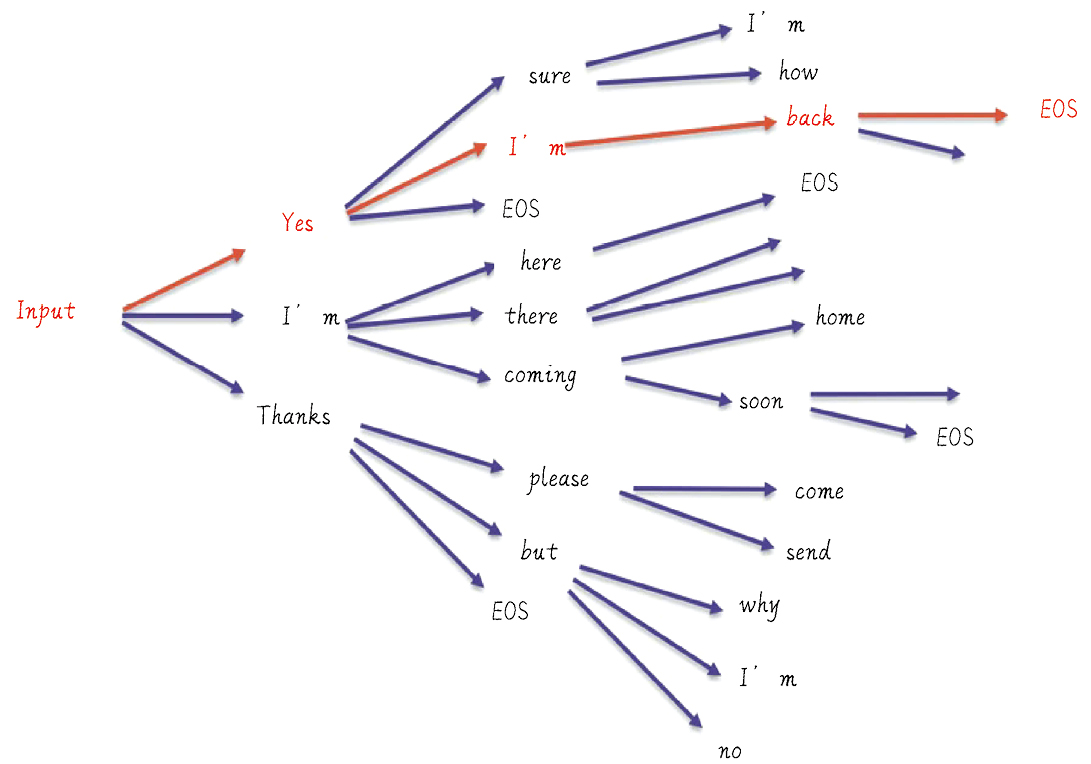
《GPT 图解》笔记:GPT-从 Decoder 到自回归文本生成
Ying’s Blog
·
Mythos阴影里谷歌悄悄发模型,速度暴涨4倍
量子位
·


谷歌的DiffusionGemma比其他Gemma模型快4倍
The New Stack
·

NVIDIA 加速谷歌 DeepMind 的 DiffusionGemma 本地 AI
NVIDIA Blog
·

Modular:Inkwell:为何推理平台与模型同样重要
Modular Blog
·
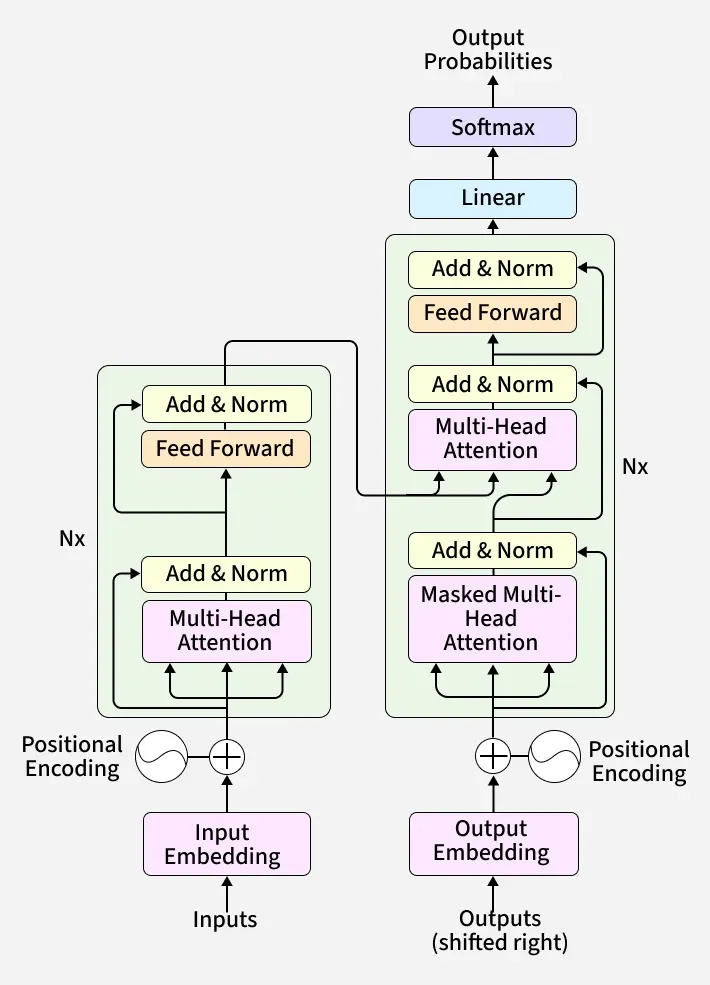
从递归神经网络到变换器
Louis Aeilot's Blog
·

创造力是温柔的谎言
Surmon.me
·

为什么大模型的损失函数是交叉熵
木鸟杂记
·

面向未来的思考:变压器的潜在前瞻训练
Apple Machine Learning Research
·

如何构建和优化AI中的RAG以获得可靠的答案
meilisearch blog
·
