
《GPT 图解》笔记:GPT-从 Decoder 到自回归文本生成
内容提要
本文讨论了GPT模型的结构及其自回归文本生成过程。GPT基于Decoder架构,采用贪婪解码和集束搜索策略生成文本。通过右移输入实现自回归,模型将输入和输出视为一个长序列,适用于多种生成任务。GPT的核心在于利用Causal Mask实现并行计算,简化了传统的编码-解码结构。
关键要点
-
GPT模型基于Decoder架构,适合自回归文本生成。
-
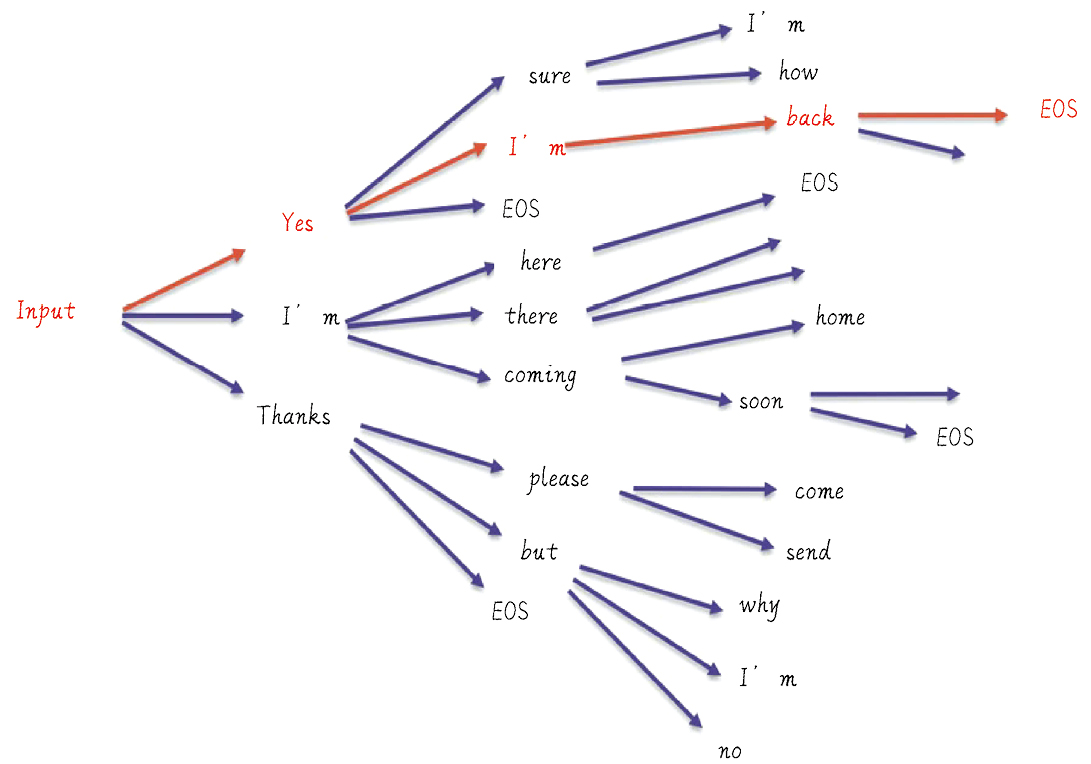
贪婪解码选择局部最优解,而集束搜索保留多个高概率候选token。
-
自回归过程通过右移输入和Causal Mask实现,并行计算。
-
GPT模型仅包含解码器部分,适用于无条件文本生成任务。
-
训练数据通过右移操作构造,确保目标序列与输入序列对齐。
-
贪婪解码和集束搜索是两种文本生成策略,分别适用于不同的生成需求。
延伸解读
自回归生成的优势
GPT模型采用自回归生成方式,通过右移输入和Causal Mask实现并行计算。这种方法使得模型在生成文本时能够高效地利用上下文信息,适合处理长序列生成任务。相比传统的编码-解码结构,GPT的解码器设计简化了计算流程,提高了生成速度。
贪婪解码与集束搜索的比较
贪婪解码和集束搜索是两种不同的文本生成策略。贪婪解码每次选择概率最高的token,简单快速,但可能错过全局最优解。而集束搜索则保留多个高概率候选token,虽然计算复杂度更高,但能生成更优质的文本。选择合适的解码策略需根据具体应用场景而定。
训练数据构造的重要性
GPT模型的训练数据通过右移操作构造,确保目标序列与输入序列对齐。这一过程对于模型的学习至关重要,因为它直接影响到模型对上下文的理解和生成能力。理解数据构造的细节,有助于更好地掌握模型的训练和推理过程。
延伸问答
GPT模型的基本架构是什么?
GPT模型基于Decoder架构,适合自回归文本生成。
贪婪解码和集束搜索有什么区别?
贪婪解码选择局部最优解,而集束搜索保留多个高概率候选token。
自回归过程是如何实现的?
自回归过程通过右移输入和Causal Mask实现,并行计算。
GPT模型适合哪些生成任务?
GPT模型适用于无条件文本生成任务。
训练数据是如何构造的?
训练数据通过右移操作构造,确保目标序列与输入序列对齐。
Causal Mask在GPT中有什么作用?
Causal Mask用于遮挡未来的token,确保模型只能看到当前及之前的token。
