
LUCID Attention:给长上下文模型戴上降噪耳机
内容提要
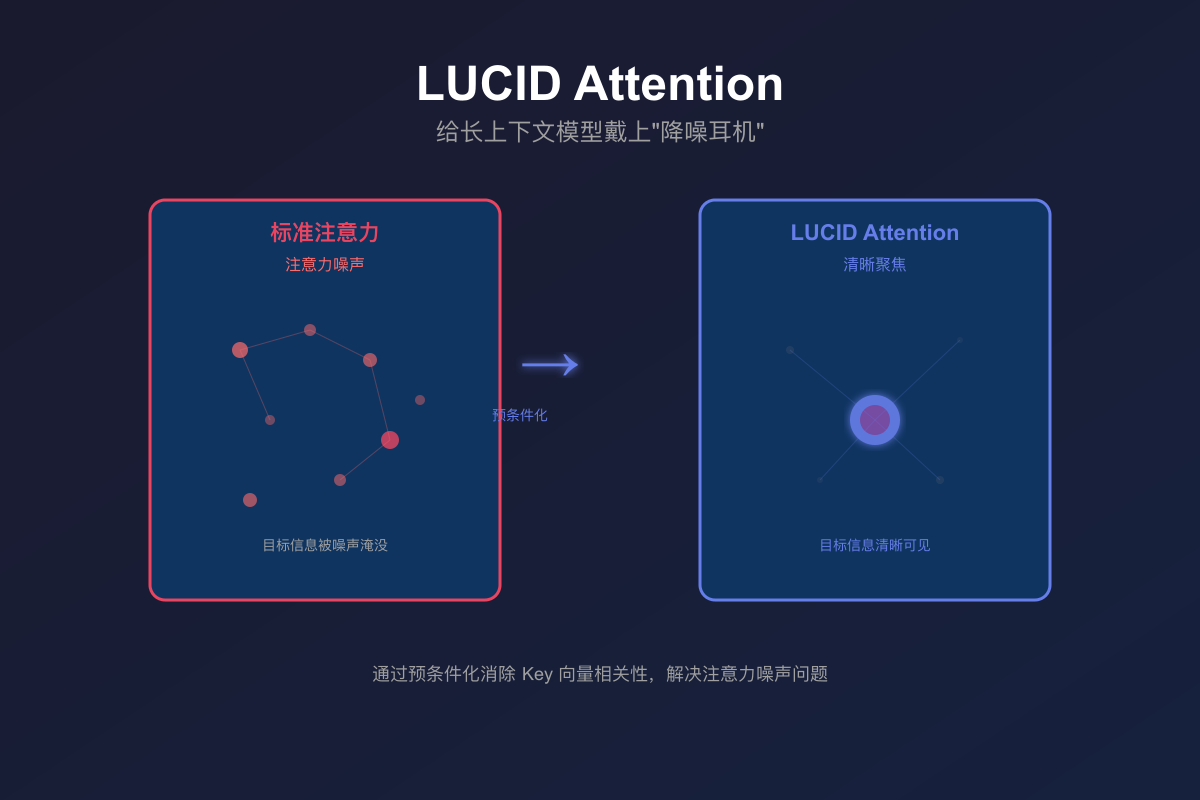
LUCID Attention 提出了一种新型注意力机制,通过去相关化 key 向量,解决了长上下文模型中的噪声和学习困境,提高了信息检索精度,计算开销几乎不变,适用于长上下文任务。
关键要点
-
LUCID Attention 提出了一种新型注意力机制,通过去相关化 key 向量,解决了长上下文模型中的噪声和学习困境。
-
LUCID Attention 使模型在超长上下文中精准找到重要信息,计算开销几乎不变。
-
标准 softmax 注意力机制在处理长上下文时存在噪声和学习困境。
-
LUCID 的核心洞察是 key 向量之间的相关性导致注意力噪声。
-
LUCID 通过构建预条件器消除 key 向量之间的相关性,从而提高检索精度。
-
LUCID 的计算复杂度保持 O(N²d),与标准注意力相同,训练和推理开销增加很小。
-
在多个长上下文基准测试中,LUCID 显著提升了检索精度和模型性能。
-
LUCID 适用于长上下文任务、精确检索需求和多跳推理。
-
LUCID 的设计可以与多种现有技术互补,提升性能。
-
LUCID 的贡献在于提供了新的理论视角,展示了预条件化在深度学习中的应用潜力。
延伸解读
LUCID Attention的核心优势
LUCID Attention通过去相关化key向量,显著提升了长上下文模型的信息检索精度。这一机制不仅解决了传统softmax注意力在处理长文本时的噪声问题,还保持了计算复杂度不变,适合需要高精度检索的任务。
与传统方法的比较
与标准softmax注意力相比,LUCID Attention在处理长上下文时表现出更高的准确性。传统方法在长文本中容易分散注意力,而LUCID通过独特的预条件化设计,确保模型能够聚焦于关键信息,避免了学习过程中的梯度消失问题。
实际应用场景
LUCID Attention特别适用于长上下文任务、精确检索需求和多跳推理等场景。当序列长度超过8K时,其优势开始显现,能够有效从大量信息中提取出关键内容,提升模型的实用性和效率。
延伸问答
LUCID Attention 是什么?
LUCID Attention 是一种新型注意力机制,通过去相关化 key 向量,解决长上下文模型中的噪声和学习困境。
LUCID Attention 如何提高信息检索精度?
LUCID Attention 通过消除 key 向量之间的相关性,使模型在超长上下文中能够精准找到重要信息。
LUCID Attention 的计算复杂度如何?
LUCID 的计算复杂度保持在 O(N²d),与标准注意力相同,训练和推理开销增加很小。
LUCID Attention 在长上下文任务中的应用场景有哪些?
LUCID Attention 适用于长上下文任务、精确检索需求和多跳推理等场景。
LUCID Attention 与标准 softmax 注意力机制有什么区别?
LUCID Attention 通过预条件化消除了 key 向量的相关性,解决了标准 softmax 注意力在长上下文中存在的噪声和学习困境。
LUCID Attention 的实验结果如何?
在多个长上下文基准测试中,LUCID 显著提升了检索精度和模型性能,例如在多针检索任务中准确率提升了 26 个百分点。
