递归语言模型与不确定性相遇:自反程序搜索在长上下文中的惊人有效性
Apple Machine Learning Research
·


注意力机制之后是什么?这家初创公司表示它已经知道了。
The New Stack
·

从 LongCat-2.0 看大模型工程化:国产算力、长上下文与编程代理
mongona news
·

一分钟读论文:《元认知记忆策略优化》
Micropaper
·

DeepSeek-V4 技术解析:架构革新与 Coding Agent 后训练优化
jax - 走在路上
·

DeepSeek-V4来了:一百万Token上下文,意味着AI终于能“读完整本书”了吗?
dotNET跨平台
·
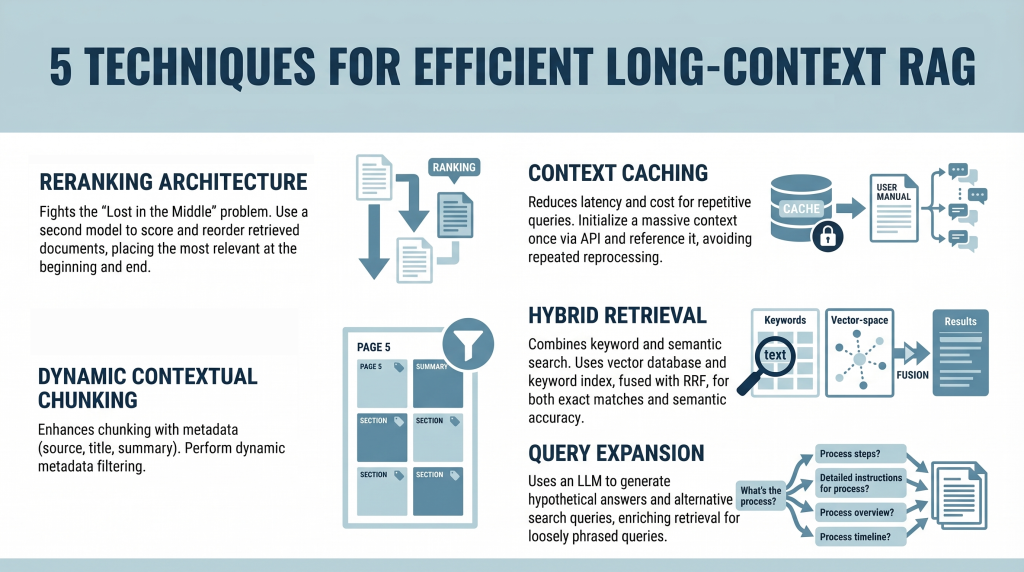
五种高效的长上下文检索增强生成技术
MachineLearningMastery.com
·



长上下文长度的旋转位置嵌入
MachineLearningMastery.com
·