
五种高效的长上下文检索增强生成技术
内容提要
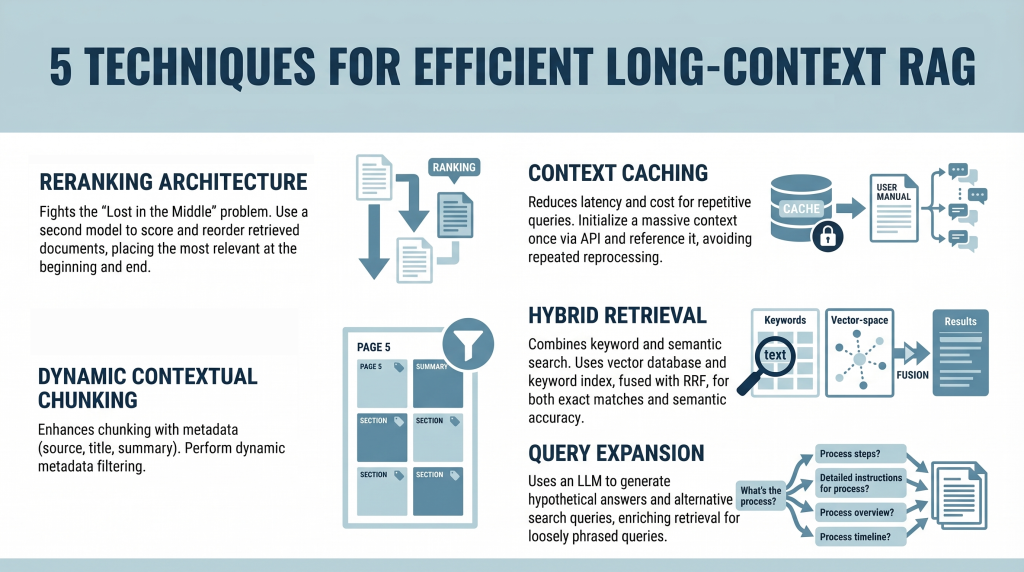
本文介绍了五种高效的长上下文检索增强生成(RAG)技术,旨在解决注意力限制和成本挑战。这些技术包括通过重新排序解决“中间丢失”问题、利用上下文缓存减少延迟和计算成本,以及结合元数据过滤和查询扩展提高相关性,从而构建可扩展且精准的RAG系统,确保模型关注最相关的信息。
关键要点
-
长上下文检索增强生成(RAG)系统面临注意力限制和成本挑战。
-
重新排序架构可以解决“中间丢失”问题,通过将最相关的信息放在提示的开头和结尾来确保最大关注。
-
上下文缓存可以减少延迟和计算成本,通过创建持久的上下文来提高效率。
-
动态上下文分块结合元数据过滤,增强相关性,减少无关信息。
-
结合关键词和语义搜索的混合检索方法,确保语义相关性和词汇准确性。
-
查询扩展技术通过生成替代搜索查询,改善信息检索的效果。
延伸解读
注意力限制的挑战
长上下文检索增强生成(RAG)系统面临的“中间丢失”问题,表明在处理长文本时,模型往往忽视中间信息。这一现象强调了在设计RAG系统时,必须考虑信息的排列顺序,以确保最相关的信息能够获得最大关注。
上下文缓存的优势
上下文缓存技术能够显著降低处理长文本时的延迟和计算成本。通过创建持久的上下文,系统可以在重复查询中避免重新处理大量信息,从而提高效率。这对于需要频繁访问静态知识库的应用场景尤为重要。
混合检索方法的必要性
结合关键词和语义搜索的混合检索方法,可以有效提高信息检索的准确性。单一的检索方式可能会遗漏重要信息,因此采用双重检索策略,确保既能捕捉语义相关性,又能满足精确匹配的需求,是构建高效RAG系统的关键。
延伸问答
什么是长上下文检索增强生成(RAG)系统?
长上下文检索增强生成(RAG)系统是一种结合检索和生成的技术,旨在处理长文本的上下文信息,以提高信息检索的效率和准确性。
如何解决RAG系统中的“中间丢失”问题?
通过实施重新排序架构,将最相关的信息放在提示的开头和结尾,确保模型关注这些信息,从而解决“中间丢失”问题。
上下文缓存如何提高RAG系统的效率?
上下文缓存通过创建持久的上下文,减少重复处理大量令牌的延迟和计算成本,从而提高系统效率。
动态上下文分块和元数据过滤的结合有什么好处?
这种结合可以通过智能分块和结构化元数据来增强相关性,减少无关信息,提高检索的精确度。
混合检索方法是如何工作的?
混合检索方法结合了语义搜索和关键词检索,通过优先考虑在两个系统中得分高的结果,确保语义相关性和词汇准确性。
查询扩展技术如何改善信息检索效果?
查询扩展技术通过生成替代搜索查询,帮助用户更好地表达信息需求,从而检索到更相关的文档。
