

当遗忘变得免费:利用低影响点降低计算成本
Apple Machine Learning Research
·
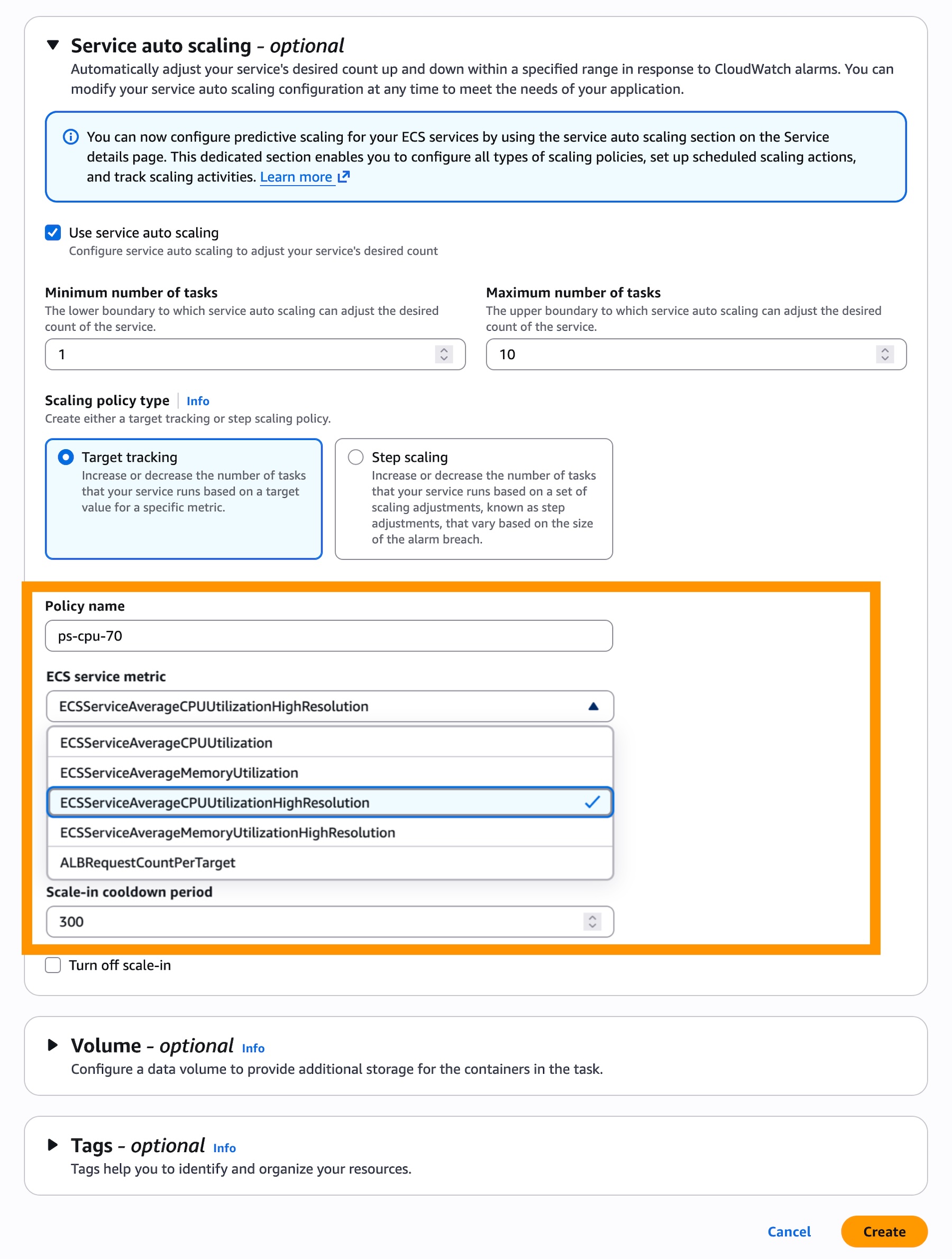
Amazon ECS 引入新的高分辨率指标,以实现服务快速自动扩缩
亚马逊AWS官方博客
·

AI 范式雷达:《自适应潜在推理:让 Agent 少想但想深》
Micropaper
·
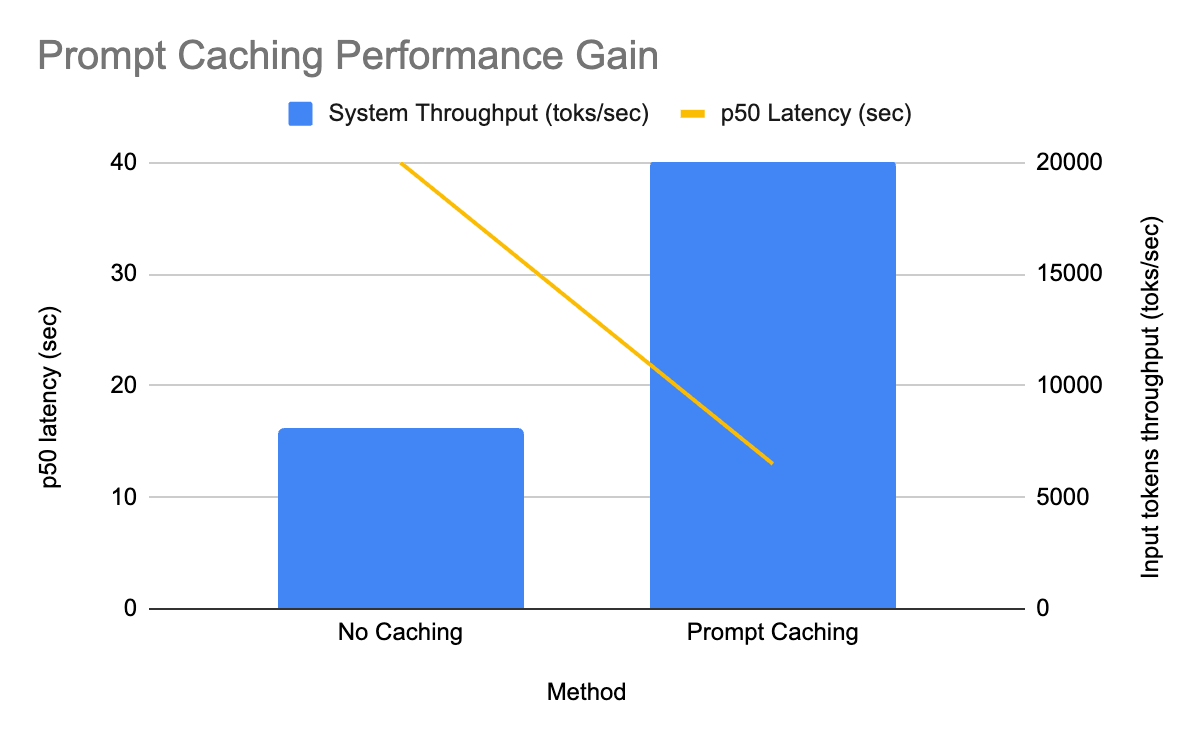
在Databricks上通过提示缓存加速开源模型的LLM推理
Databricks
·

MinIO的MemKV通过消除AI重复计算成本,承诺实现95%的GPU利用率提升
The New Stack
·

自适应并行推理:高效推理扩展的新范式
The Berkeley Artificial Intelligence Research Blog
·
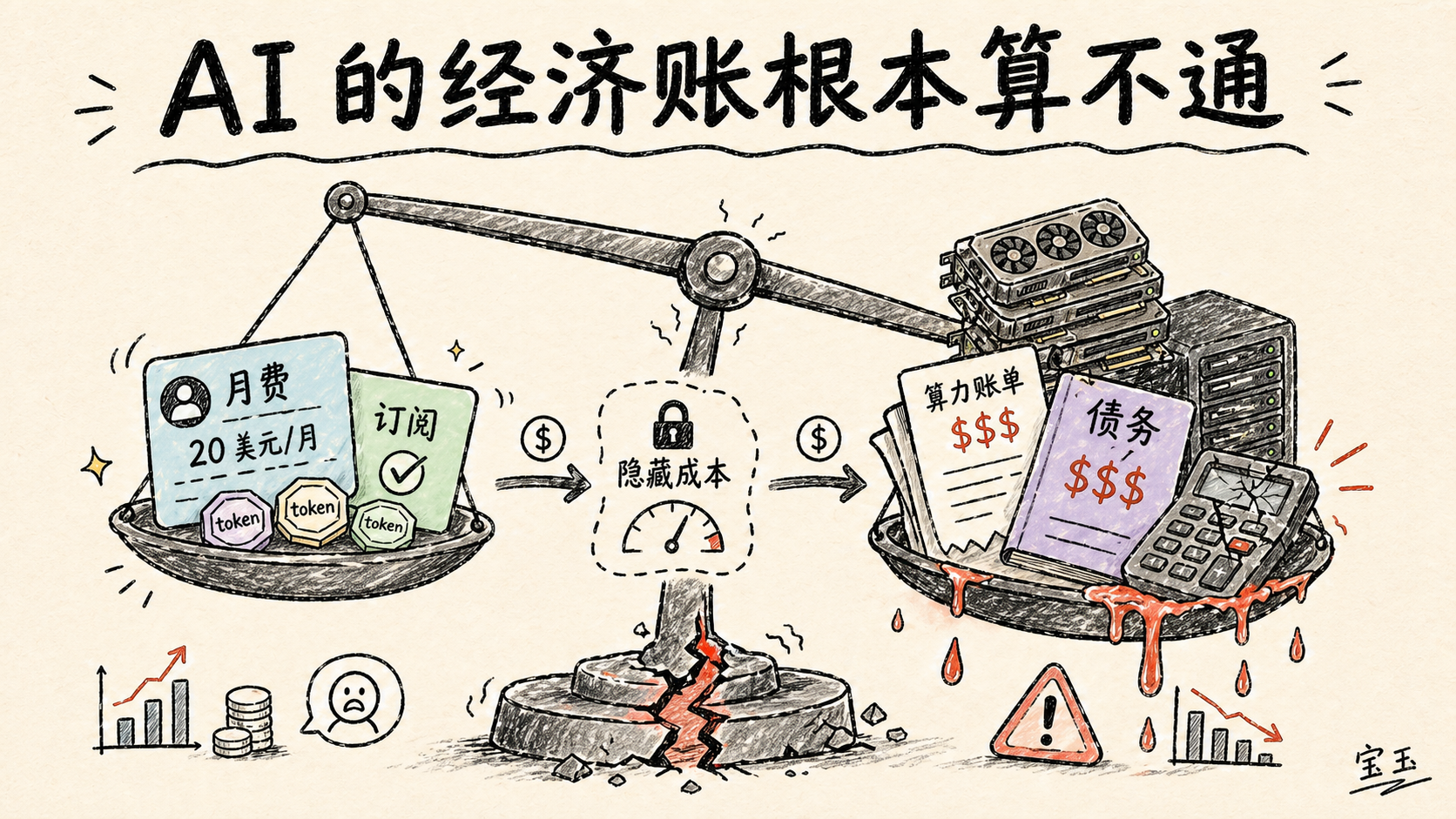
AI 的经济账根本算不通
宝玉的分享
·


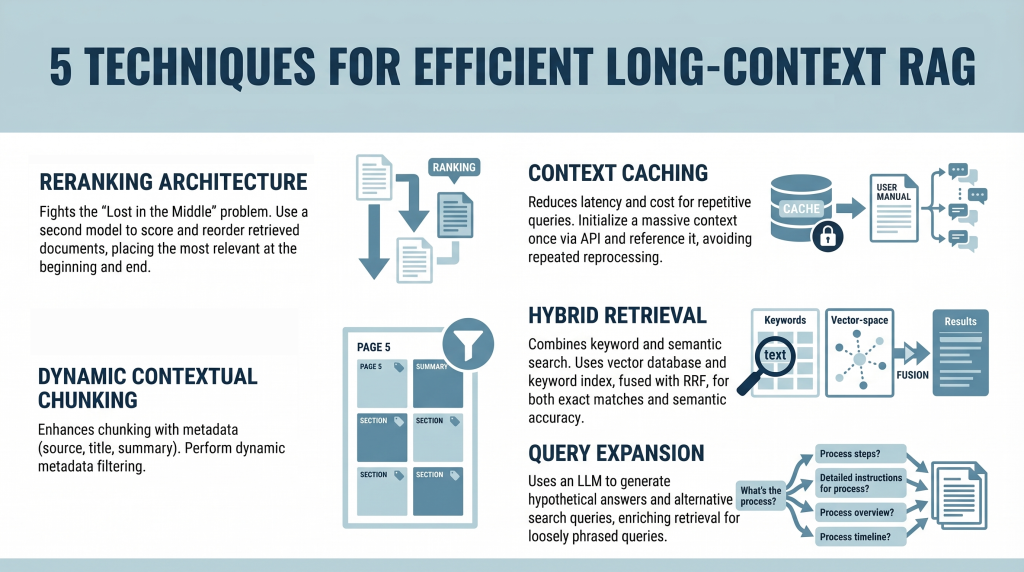
五种高效的长上下文检索增强生成技术
MachineLearningMastery.com
·

自反取证增强生成解析:自我反思检索如何提升人工智能输出
meilisearch blog
·

打破密集瓶颈:Voyage-4-large如何利用混合专家(MoE)进行扩展
Voyage AI
·

NVIDIA推出Earth-2开放模型系列——全球首个完全开放、加速的人工智能天气模型和工具集
NVIDIA Blog
·
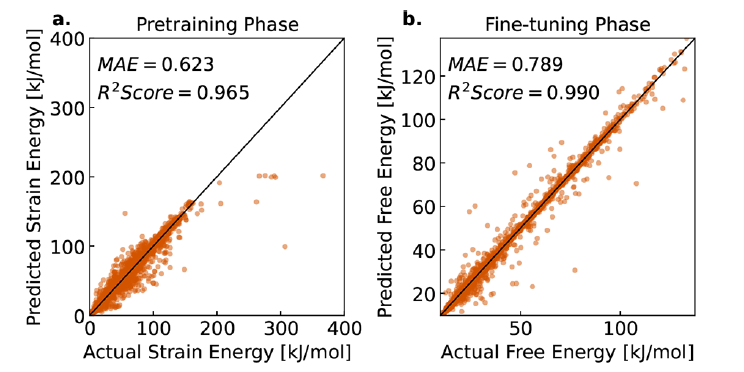
准确率达 97%!普林斯顿大学等提出 MOFSeq-LMM,高效预测MOFs能否被合成
HyperAI超神经
·

计算成本减半,化学反应发现工具ChemOntology将人类直觉「编码」到系统中,加速反应路径搜索
HyperAI超神经
·

使小型语言模型能够解决复杂推理任务
MIT News - Computer Science and Artificial Intelligence Laboratory (CSAIL)
·
