
在Databricks上通过提示缓存加速开源模型的LLM推理
内容提要
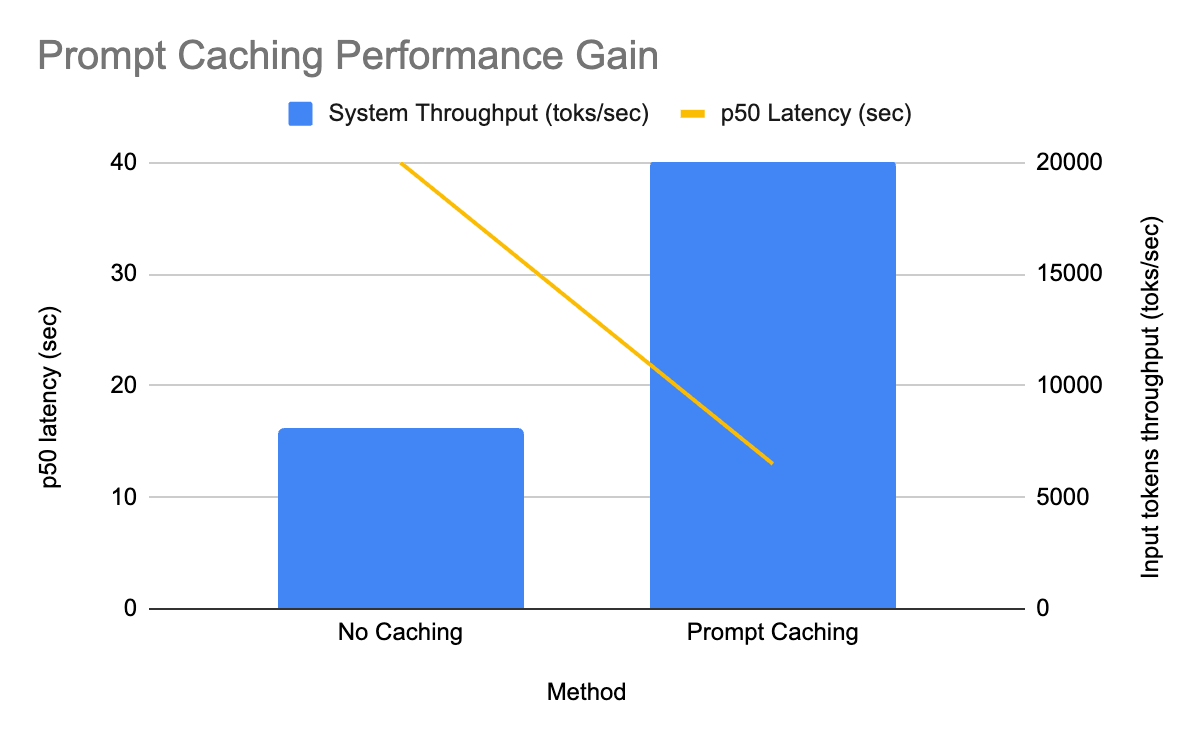
在旧金山举行的全球最大数据、应用和人工智能活动中,研究人员探讨了提示缓存技术在大型语言模型(LLM)推理中的应用。提示缓存可以消除重复请求的冗余,提高模型在特定领域的质量,并降低计算成本。Databricks为开源模型提供此功能,确保安全性并自动优化性能,提升推理效率。
关键要点
-
提示缓存技术可以消除重复请求的冗余,提高大型语言模型(LLM)推理的效率。
-
通过共享领域特定的系统提示,提示缓存可以降低计算成本并提高模型在特定领域的质量。
-
Databricks为开源模型提供内置的提示缓存功能,确保安全性并自动优化性能。
-
提示缓存支持在Databricks上托管的多个开源模型,提升推理效率。
-
提示缓存的实现是隐式的,用户无需进行额外配置,系统会自动运行提示缓存以提高吞吐量。
延伸解读
提示缓存的优势
提示缓存技术通过消除重复请求的冗余,显著提高了大型语言模型的推理效率。这意味着在处理大量相似请求时,系统能够更快地响应,从而降低延迟和计算成本,尤其适用于需要高吞吐量的应用场景。
安全性与隐私保护
Databricks在实现提示缓存时,特别注重安全性。缓存数据仅存储在易失性内存中,确保不会被持久化,这降低了数据泄露的风险。用户无需进行额外配置,系统自动管理缓存,进一步简化了使用过程。
适用场景与应用
提示缓存不仅适用于实时聊天和批量处理文档,还能提升AI代理的性能。对于需要处理大量相似请求的企业任务,提示缓存能够显著提升推理质量和效率,值得在实际应用中进行尝试。
延伸问答
什么是提示缓存技术?
提示缓存技术是一种消除重复请求冗余的技术,能够提高大型语言模型(LLM)推理的效率。
提示缓存如何降低计算成本?
提示缓存通过共享领域特定的系统提示,降低了每个请求的计算成本。
Databricks如何实现提示缓存功能?
Databricks为开源模型提供内置的提示缓存功能,确保安全性并自动优化性能,无需用户额外配置。
使用提示缓存有什么好处?
使用提示缓存可以提高推理效率,降低成本,并在特定领域提升模型质量。
提示缓存对开源模型的支持情况如何?
提示缓存支持在Databricks上托管的多个开源模型,提升其推理效率。
提示缓存的安全性如何保障?
提示缓存是隔离的,仅存在于易失性内存中,且不会被持久化,确保了安全性。
