

在Kubernetes中使用vLLM运行自托管的大型语言模型(LLM)
Cloud Native Computing Foundation
·

尴尬的简单自我蒸馏提升代码生成
Apple Machine Learning Research
·
大型语言模型函数调用的不确定性量化
Apple Machine Learning Research
·
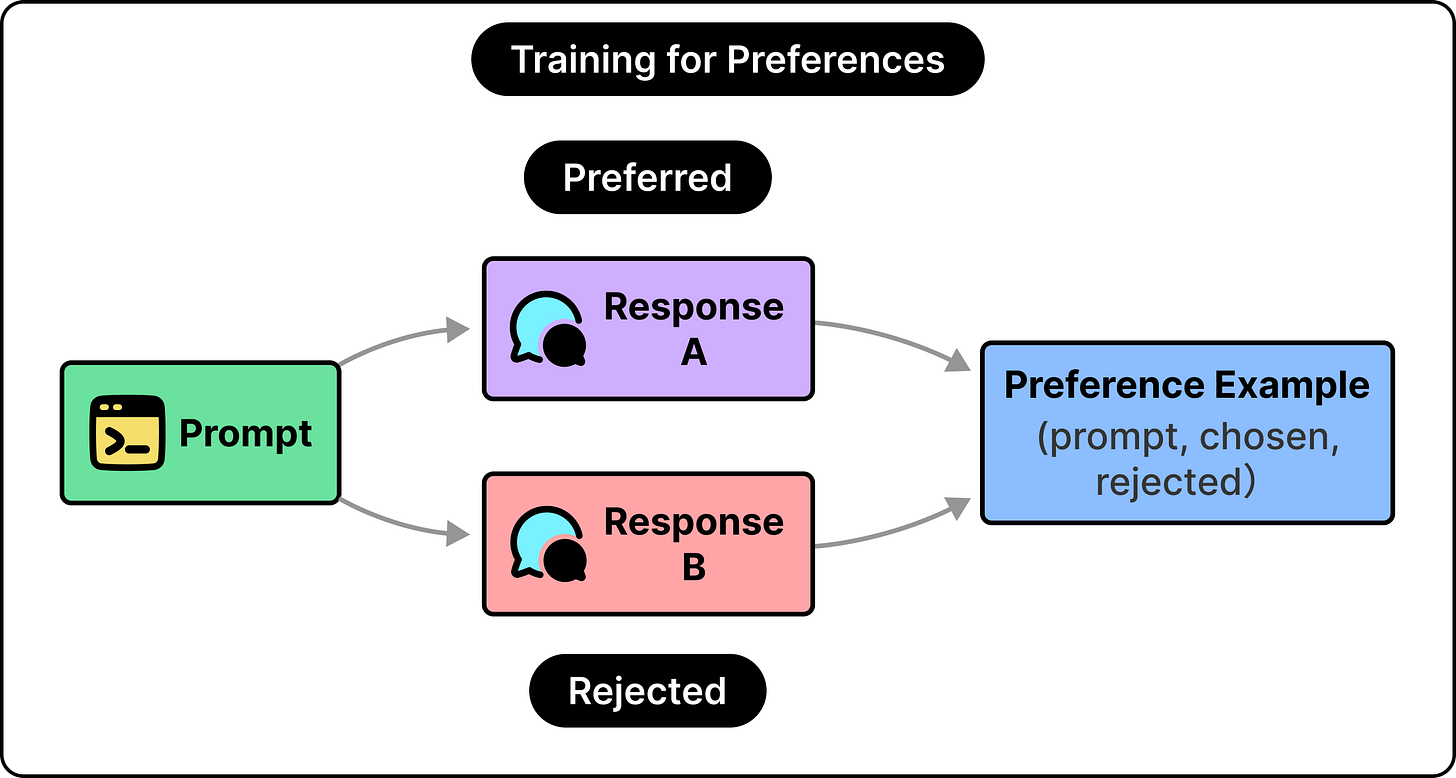
大型语言模型如何学习提供帮助(RLHF与DPO)
ByteByteGo Newsletter
·

领域特定语言(DSL)促进大型语言模型(LLM)的可靠使用
Martin Fowler
·

论文图表可视化工具
What's new by TerryTao
·


大型语言模型(LLM)框架比较:LangChain、LlamaIndex与原始API调用
MachineLearningMastery.com
·

AI论文评审:自一致性提升语言模型中的链式思维推理
freeCodeCamp.org
·
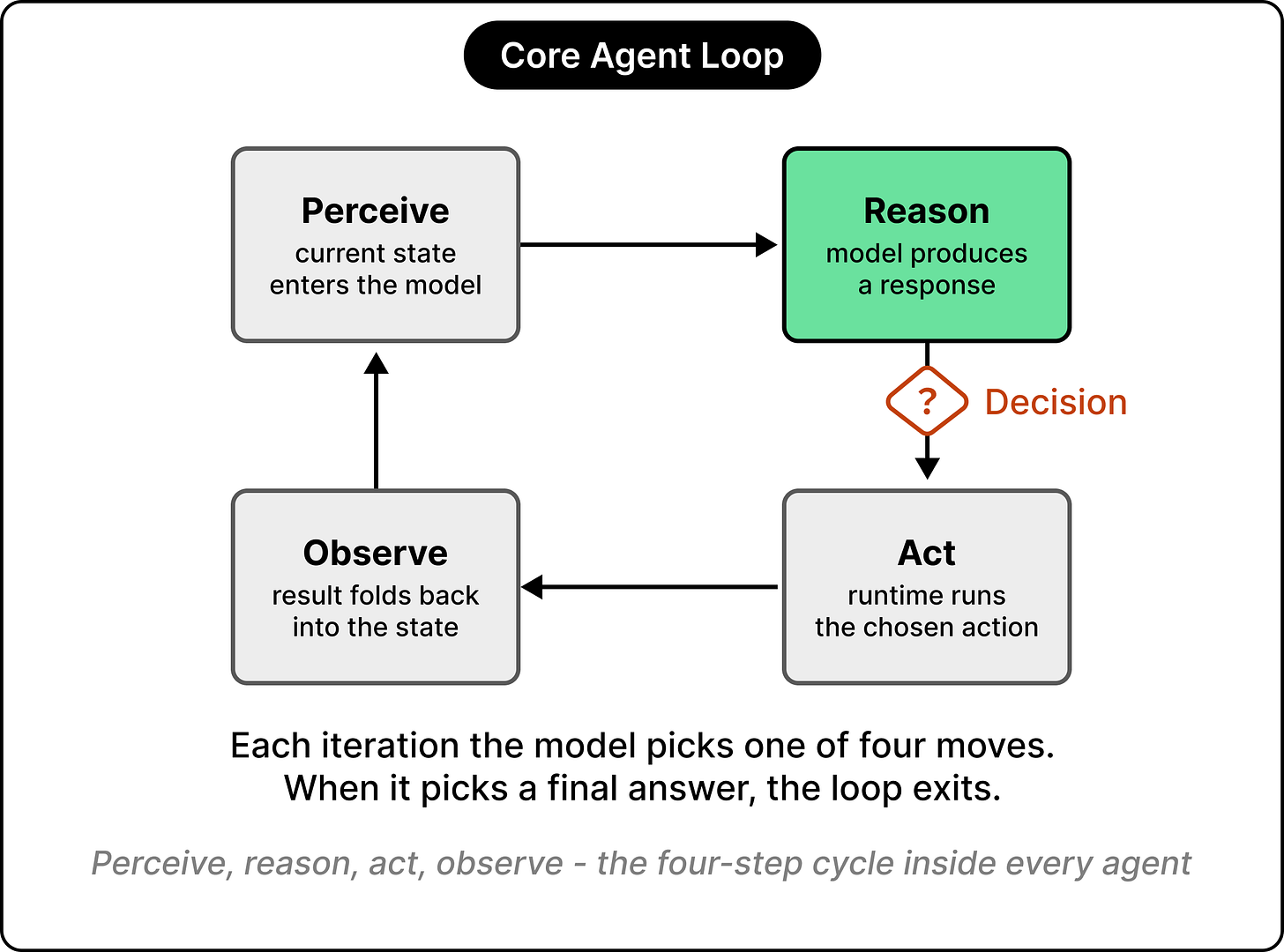
代理循环:人工智能如何从回答问题转向执行任务
ByteByteGo Newsletter
·

初学者的AI代理
freeCodeCamp.org
·
DynaMiCS:使用动态混合进行具有性能约束的大型语言模型微调
Apple Machine Learning Research
·
单个神经元足以绕过大型语言模型中的安全对齐
Apple Machine Learning Research
·
为什么传统的CI/CD无法满足大型语言模型的需求(以及我们为解决这个问题而建立的发布门控)
The New Stack
·
