
大型语言模型的上下文工程指南
内容提要
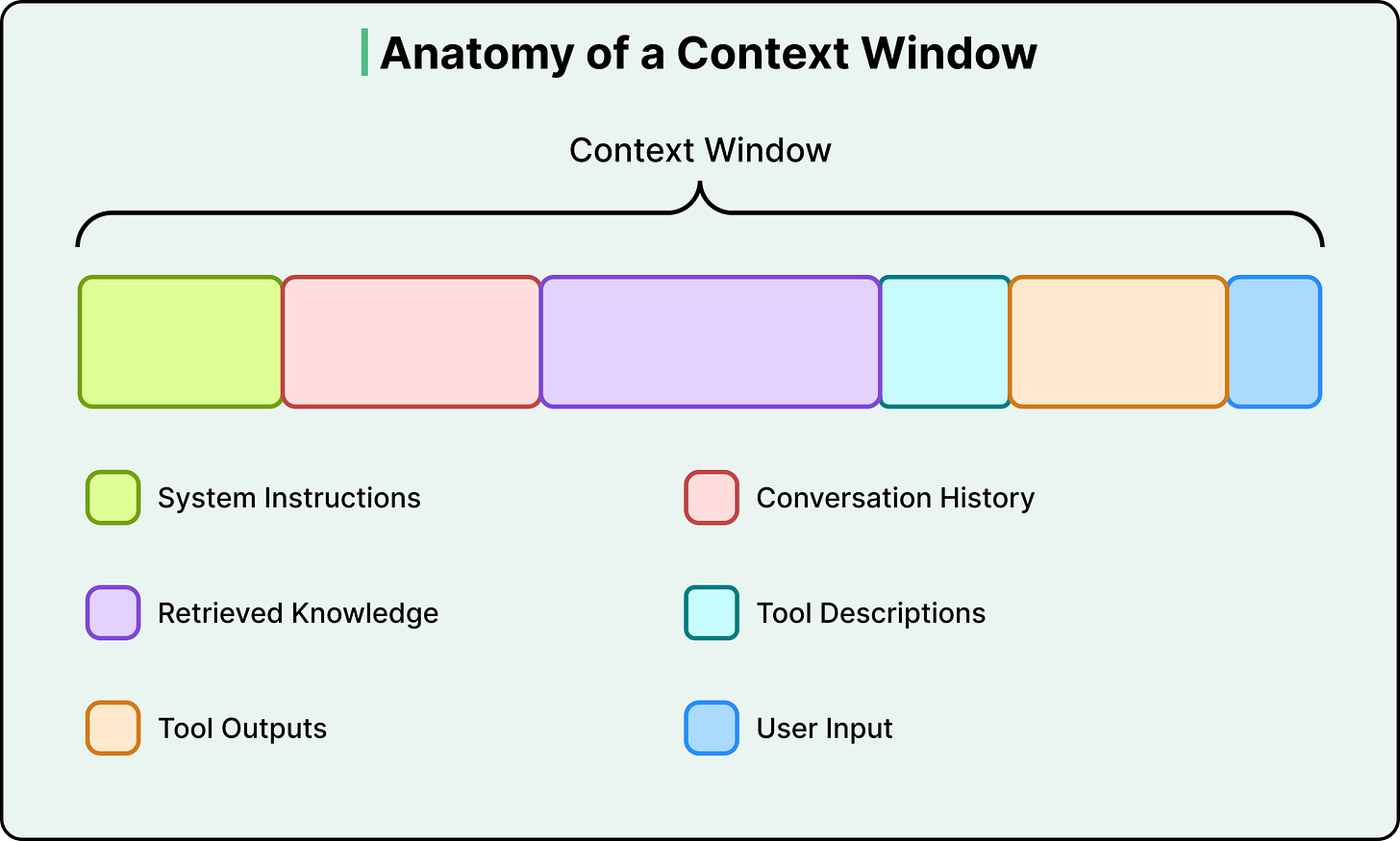
本文探讨了上下文工程在大型语言模型中的重要性。研究表明,过多的输入信息会降低模型性能,尤其是当相关信息位于输入中间时。上下文窗口的设计及信息选择与压缩策略至关重要,有效的上下文工程能够提升模型响应质量,避免信息丢失和注意力稀释。
关键要点
-
给大型语言模型(LLM)提供过多信息会降低其性能,尤其是当相关信息位于输入中间时。
-
上下文窗口的设计和信息选择与压缩策略至关重要,过长的输入会导致模型性能下降。
-
上下文工程是设计、组装和管理LLM所见信息环境的实践,旨在确保模型获得所需信息而不被多余信息干扰。
-
模型的注意力机制使得输入中间的信息容易被忽视,导致准确性下降。
-
有效的上下文工程策略包括写入、选择、压缩和隔离,以应对上下文窗口的有限性和信息稀释问题。
-
上下文工程的成功依赖于对信息的精确管理,错误的压缩或选择可能导致重要信息的丢失。
延伸解读
上下文窗口的重要性
上下文窗口的设计直接影响大型语言模型的性能。研究表明,输入信息的顺序和位置至关重要,尤其是中间的信息容易被忽视。用户在构建输入时,应优先考虑将关键信息放在开头或结尾,以提高模型的响应准确性。
信息选择与压缩策略
有效的信息选择和压缩策略可以显著提升模型的表现。过多的无关信息会导致注意力稀释,降低模型的准确性。因此,用户应关注如何提取最相关的信息,并在必要时进行有效的压缩,以避免信息的丢失。
多代理系统的优势
采用多代理系统可以有效分散信息处理的负担,避免信息混杂导致的注意力稀释。每个代理专注于特定任务,从而提高整体效率和准确性。这种方法在复杂任务中尤为有效,值得开发者考虑。
延伸问答
上下文工程在大型语言模型中有什么重要性?
上下文工程确保模型获得所需信息而不被多余信息干扰,从而提升模型响应质量。
为什么给大型语言模型提供过多信息会降低其性能?
过多信息会导致注意力稀释,尤其是当相关信息位于输入中间时,模型容易忽视这些信息。
上下文窗口的设计对大型语言模型有什么影响?
上下文窗口的设计决定了模型能同时处理的信息量,过长的输入会导致性能下降。
什么是上下文腐烂,如何影响模型性能?
上下文腐烂是指随着输入长度增加,模型性能下降的现象,尤其在简单任务中表现明显。
有效的上下文工程策略有哪些?
有效的策略包括写入、选择、压缩和隔离,以应对上下文窗口的有限性和信息稀释问题。
上下文工程与提示工程有什么区别?
上下文工程关注的是如何动态组装模型所需的全部信息,而提示工程则专注于如何优化单个指令的表述。
