


递归语言模型与不确定性相遇:自反程序搜索在长上下文中的惊人有效性
Apple Machine Learning Research
·




Weblica:可扩展和可重复的视觉网络代理训练环境
Apple Machine Learning Research
·
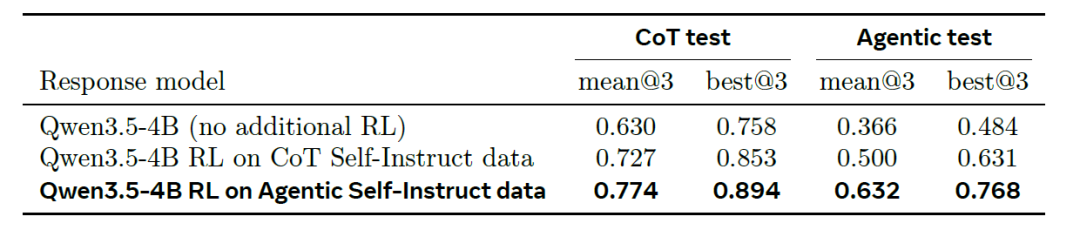
Meta提出AI数据科学家,Autodata构建高质量训练/评测数据集
HyperAI超神经
·

DevRel通讯 — 2026年6月
Elastic Blog - Elasticsearch, Kibana, and ELK Stack
·

如何构建一个使用autoresearch进行自主LLM实验的AI代理
freeCodeCamp.org
·

步骤拒绝微调:从嘈杂的智能体轨迹中提取更多信号
The JetBrains Blog
·

Claude Code 怎样快速消耗 token
iMaeGoo's Blog
·


2.7%的裂缝:全球AI竞赛进入非对称博弈时代
TechWeb 全站精华
·
GPT-5.5与DeepSeek V4,AI 竞争进入新格局!
硕鼠的博客站
·
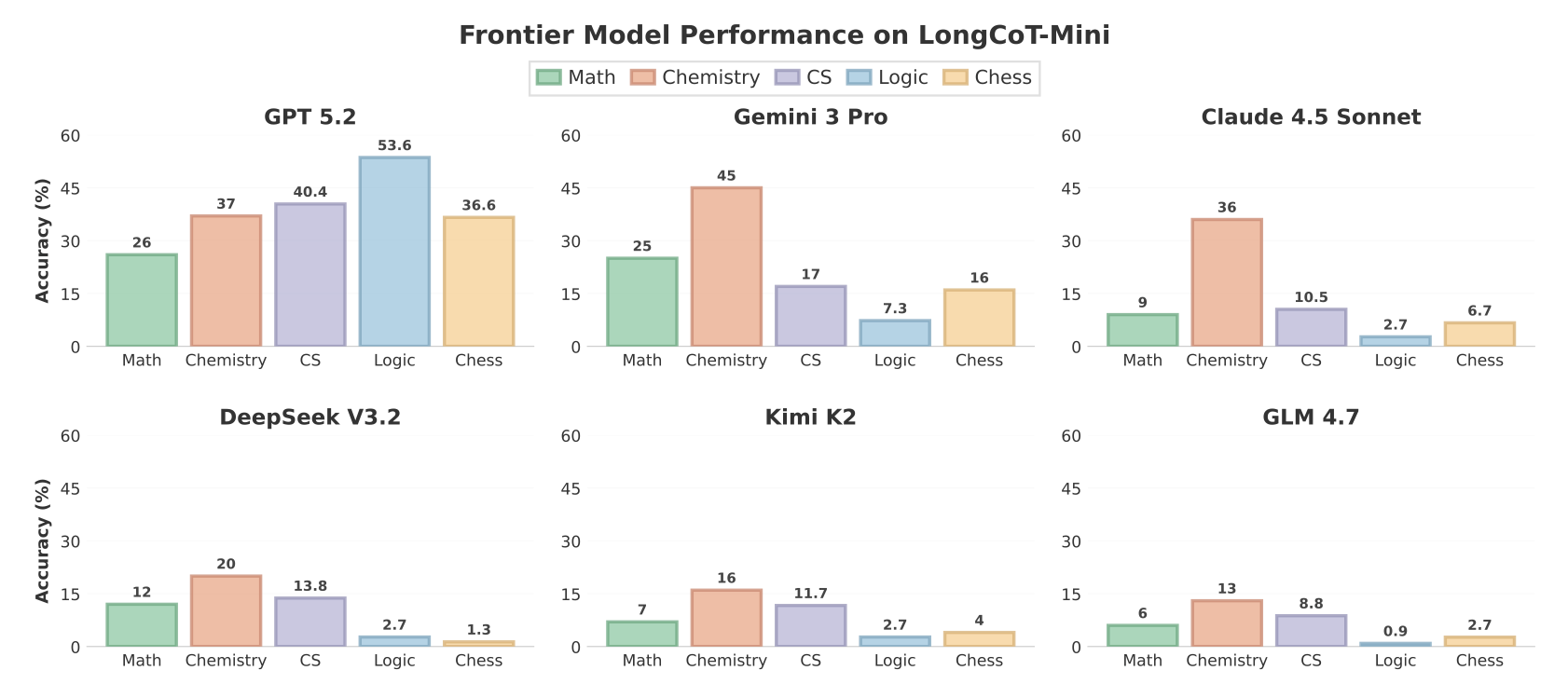
关于管理不善的天才假说的小型练习(长链推理中的语言模型)
blank
·
