
关于管理不善的天才假说的小型练习(长链推理中的语言模型)
内容提要
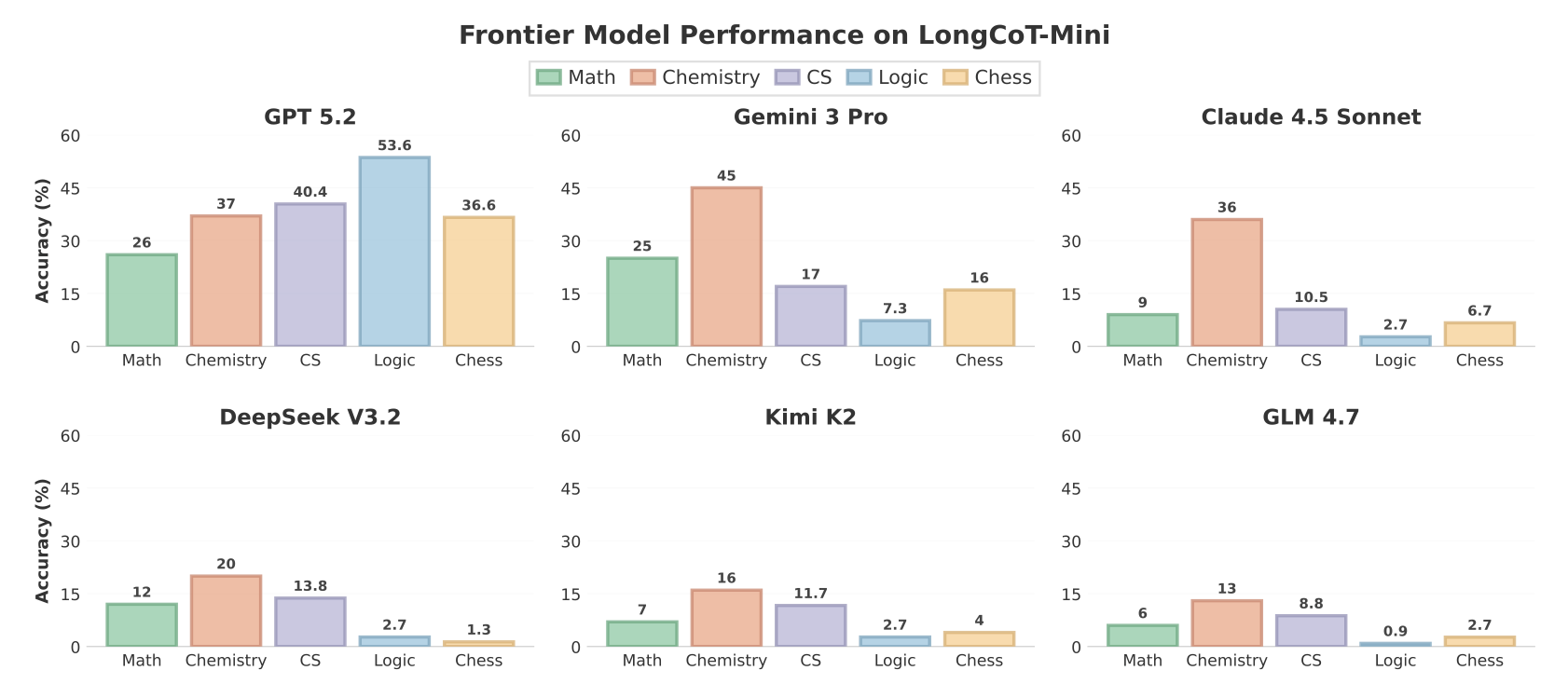
文章讨论了语言模型(LM)在复杂推理任务中的表现,特别是LongCoT基准测试。尽管最新模型(如GPT-5.2)在某些任务上表现不佳,但通过改进提示和训练,模型性能显著提升。研究表明,模型在处理图结构依赖时存在困难,提示设计对模型表现影响巨大。整体来看,模型能力的理解仍需深入。
关键要点
-
语言模型在复杂推理任务中的表现受到提示设计的显著影响。
-
LongCoT基准测试显示,最新模型(如GPT-5.2)在处理图结构依赖时存在困难。
-
尽管RLM模型在某些情况下表现不佳,但通过改进提示和训练,模型性能可以显著提升。
-
研究表明,RLM需要针对图结构的组合推理进行专门训练。
-
模型能力的理解仍需深入,当前的基准测试难以全面反映模型的真实能力。
延伸解读
语言模型的潜力与限制
尽管最新的语言模型在某些复杂推理任务中表现不佳,但这并不意味着它们的能力有限。文章指出,模型的表现受到提示设计的显著影响,合理的提示可以显著提升模型的性能。这提示我们在使用语言模型时,设计合适的输入提示至关重要。
图结构推理的挑战
研究表明,语言模型在处理图结构依赖时存在困难,尤其是在组合推理任务中。当前的基准测试未能全面反映模型的真实能力,因此在评估模型时需谨慎,特别是在涉及复杂依赖关系的任务中。
改进训练方法的必要性
文章强调,递归语言模型(RLM)需要针对图结构的组合推理进行专门训练。通过改进训练方法和提示设计,模型的表现可以得到显著提升。这表明,未来的研究应关注如何优化模型的训练过程,以更好地应对复杂推理任务。
延伸问答
语言模型在复杂推理任务中的表现如何?
语言模型在复杂推理任务中的表现受到提示设计的显著影响,尤其是在处理图结构依赖时存在困难。
LongCoT基准测试的主要发现是什么?
LongCoT基准测试显示,最新模型如GPT-5.2在处理复杂的组合推理任务时表现不佳,整体解决率低于10%。
如何提高语言模型的性能?
通过改进提示和训练,语言模型的性能可以显著提升,尤其是在图结构的组合推理任务中。
RLM模型在LongCoT任务中的表现如何?
RLM模型在LongCoT任务中的表现通常低于基线模型,尤其在数学和计算机科学问题上表现不佳。
为什么RLM模型需要专门训练?
RLM模型需要专门训练以处理图结构的组合推理,因为当前模型在这方面的能力不足。
提示设计对语言模型的影响是什么?
提示设计对语言模型的表现有显著影响,良好的提示可以引导模型更好地解决复杂问题。
