
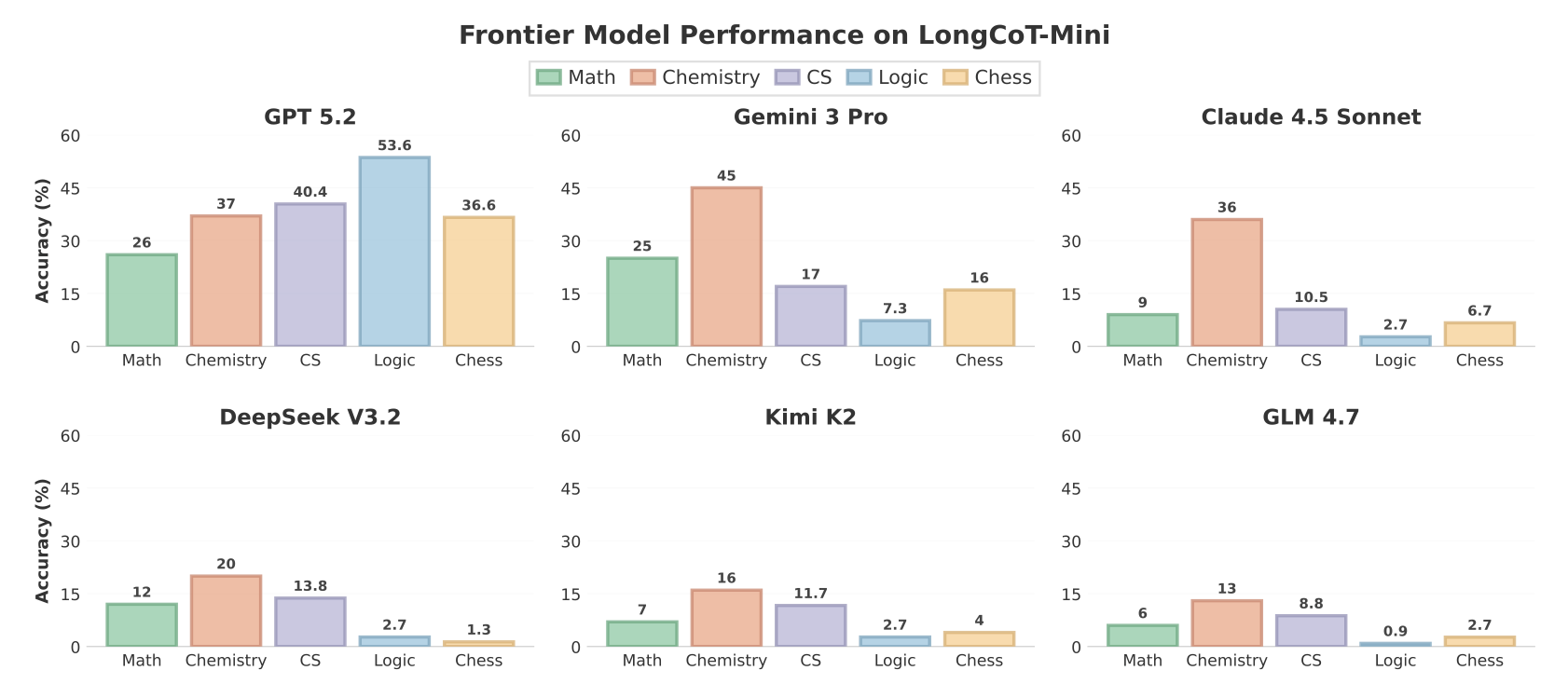
关于管理不善的天才假说的小型练习(长链推理中的语言模型)
blank
·
每位开发者都应该了解的四种提示工程模式——以及为什么“画一只猫”能解释它们所有
The New Stack
·

大型语言模型一次能“读取”多少内容?了解上下文窗口
DEV Community
·

掌握Vertex AI中的提示设计:深入探讨
DEV Community
·
生成结构化的内容(JSON模式)是否会影响 LLM 性能?[译]
宝玉的分享
·
