
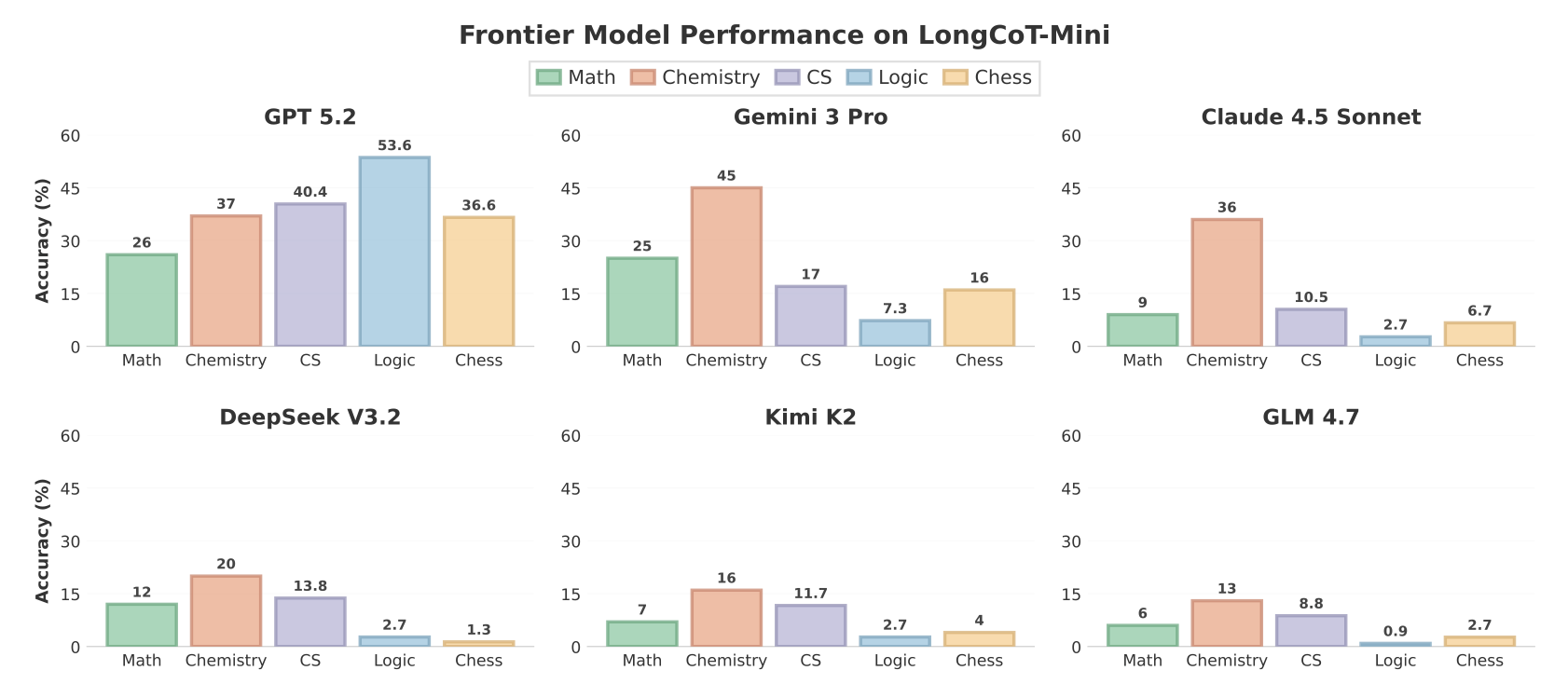
关于管理不善的天才假说的小型练习(长链推理中的语言模型)
blank
·

人工智能缩水:为何Anthropic的Claude Opus 4.7可能不如其替代模型
The New Stack
·

HRM 架构突破:用仅 2700 万参数和 1000 个训练样本超越最先进的大语言模型
Micropaper
·
基础模型 vs. 指令模型 vs. 思维模型
Alex Ewerlöf Notes
·

Claude Opus 4.5 现已在 Vercel AI Gateway 上可用
Vercel News
·

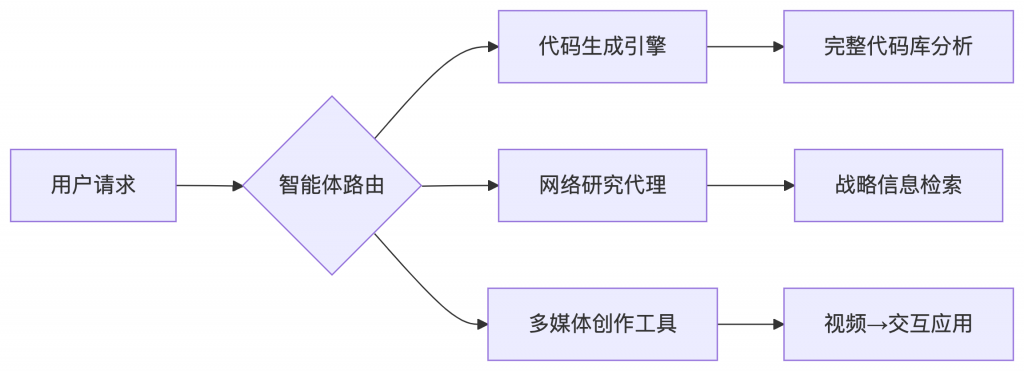
解码Google Gemini 2.5:推理、多模态与智能体能力的革命性突破
我爱自然语言处理
·
