
Hugging Face 发布 ml-intern:一款可自动化 LLM 训练后工作流程的开源 AI 代理
内容提要
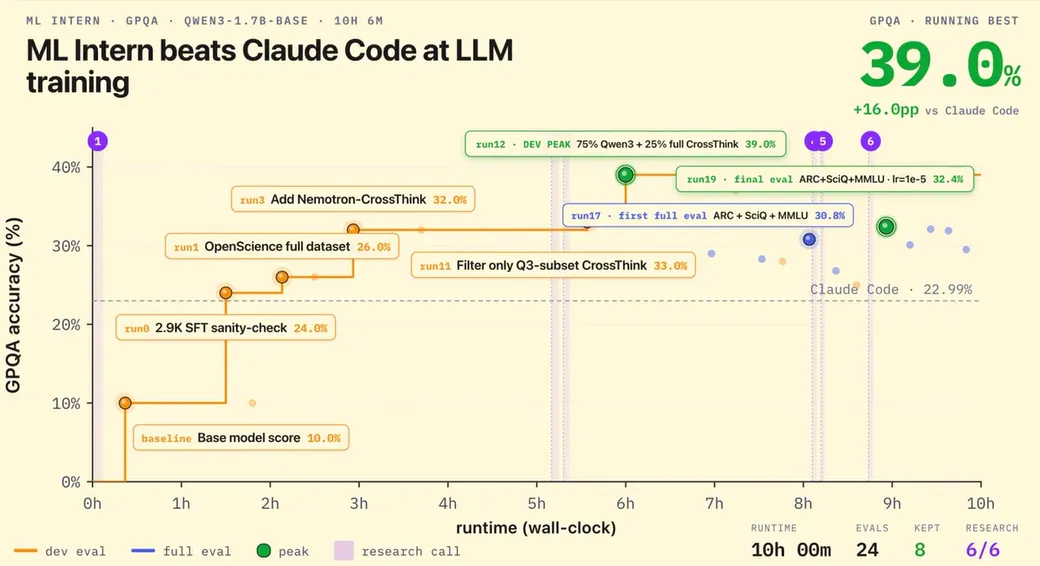
Hugging Face 发布了开源 AI 代理 ml-intern,旨在自动化大型语言模型的训练后工作流程。该工具能够自主进行文献综述、数据集发现和训练评估,显著提升模型性能。在不到10小时内,ml-intern 将 Qwen3-1.7B 模型的得分从 8.5% 提升至 32%,超越了现有技术。它还采用合成数据生成和 GRPO 等高级训练策略,展现出极高的数据效率。
关键要点
-
ml-intern 是 Hugging Face 发布的开源 AI 代理,旨在自动化大型语言模型的训练后工作流程。
-
该工具能够自主执行文献综述、数据集发现、训练脚本执行和迭代评估,显著减少人力投入。
-
ml-intern 在不到 10 小时内将 Qwen3-1.7B 模型的得分从 8.5% 提升至 32%,超越了现有技术。
-
该智能体使用合成数据生成和组相对策略优化 (GRPO) 等高级训练策略,展现出极高的数据效率。
-
整个监控堆栈依赖于 Trackio,作为 Weights & Biases 的开源替代方案。
延伸解读
自动化的潜力
ml-intern 的发布标志着大型语言模型训练后工作流程的自动化新阶段。通过自主执行文献综述和数据集发现,该工具显著减少了人力投入,提升了研究效率。这对于资源有限的团队尤其重要,能够让他们在更短时间内取得更高的研究成果。
数据效率的重要性
ml-intern 在使用 Qwen3-1.7B 模型时,展现了极高的数据效率,其得分从 8.5% 提升至 32%。这一结果表明,模型在短时间内能够有效利用合成数据和高级训练策略,超越了许多人工研究者的表现。这为未来的模型训练提供了新的思路,尤其是在数据稀缺的领域。
技术策略的应用
ml-intern 采用合成数据生成和组相对策略优化(GRPO)等技术策略,展示了其在特定领域的应用潜力。尤其是在医疗和数学领域,这些策略能够针对特定情况生成高质量数据,提升模型的适应性和准确性。研究人员应关注这些技术的实际应用,以优化模型性能。
延伸问答
ml-intern 是什么?
ml-intern 是 Hugging Face 发布的一款开源 AI 代理,旨在自动化大型语言模型的训练后工作流程。
ml-intern 如何提升模型性能?
ml-intern 通过自主执行文献综述、数据集发现和训练评估,在不到 10 小时内将 Qwen3-1.7B 模型的得分从 8.5% 提升至 32%。
ml-intern 使用了哪些高级训练策略?
ml-intern 使用了合成数据生成和组相对策略优化 (GRPO) 等高级训练策略,展现出极高的数据效率。
ml-intern 的监控堆栈依赖于什么?
ml-intern 的监控堆栈依赖于 Trackio,这是一个开源实验跟踪器,作为 Weights & Biases 的替代方案。
ml-intern 在基准测试中的表现如何?
在 PostTrainBench 基准测试中,ml-intern 在单个 H100 GPU 上的表现显著,能够在严格的 10 小时内完成基础模型的后训练。
ml-intern 如何进行数据集发现?
ml-intern 首先浏览 arXiv 和 Hugging Face Papers,识别相关的数据集和技术,然后在 Hugging Face Hub 中搜索并检查数据集质量。
