
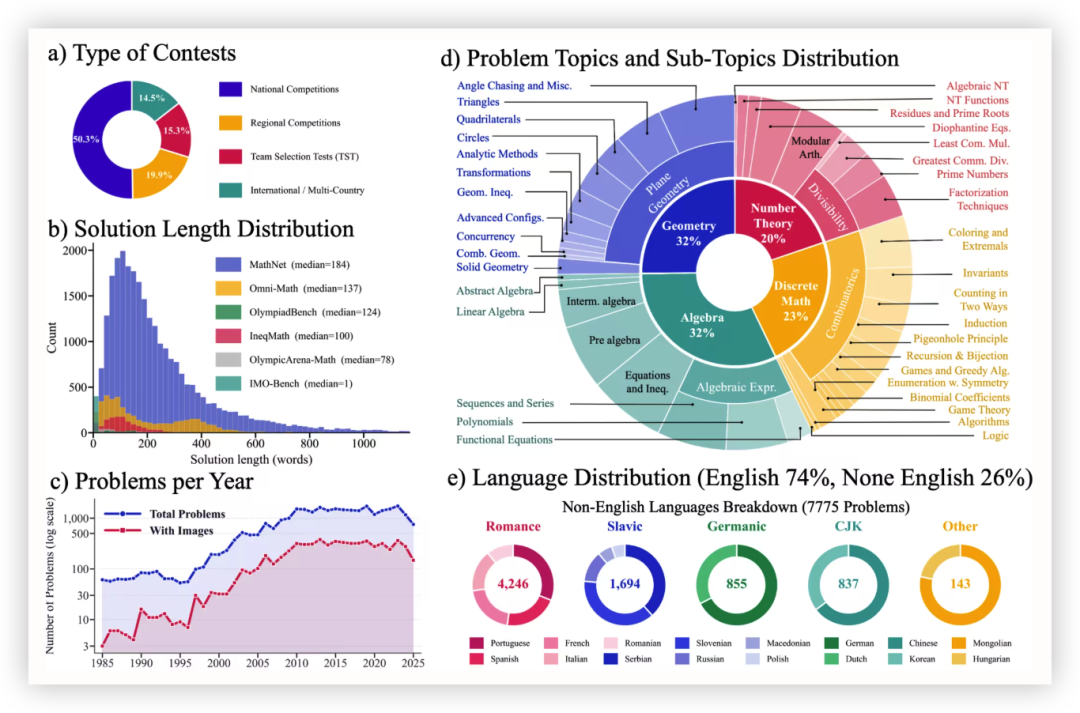
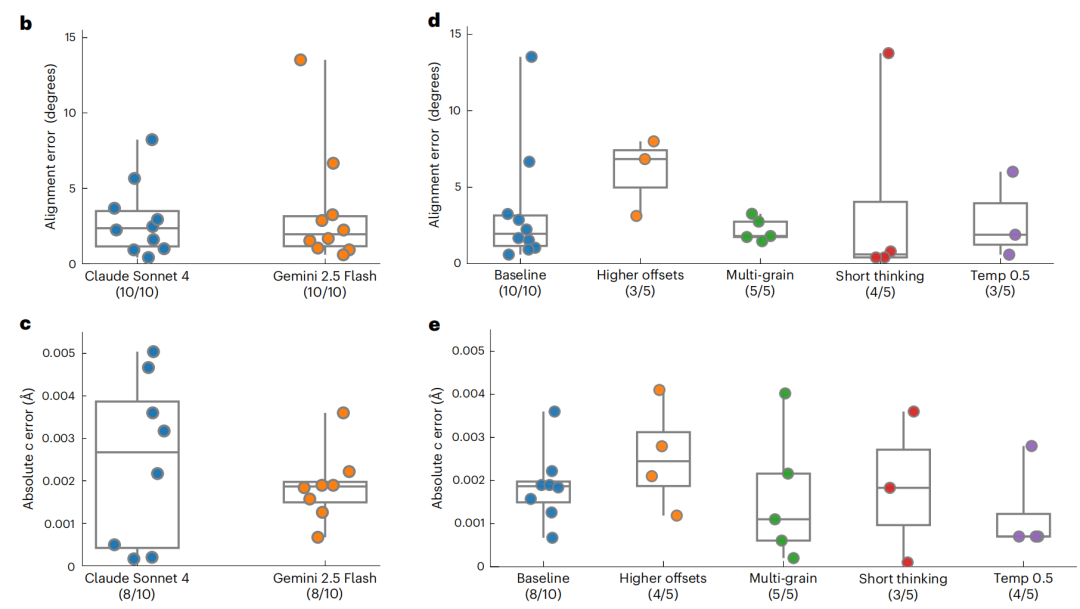
基于大模型推理与MCP工具调用,斯坦福大学AI X射线科学家在同步辐射光源自主完成单晶衍射对准
HyperAI超神经
·

Python 潮流周刊#160:AI 智能体与 LLM 推理
豌豆花下猫 | Python猫
·
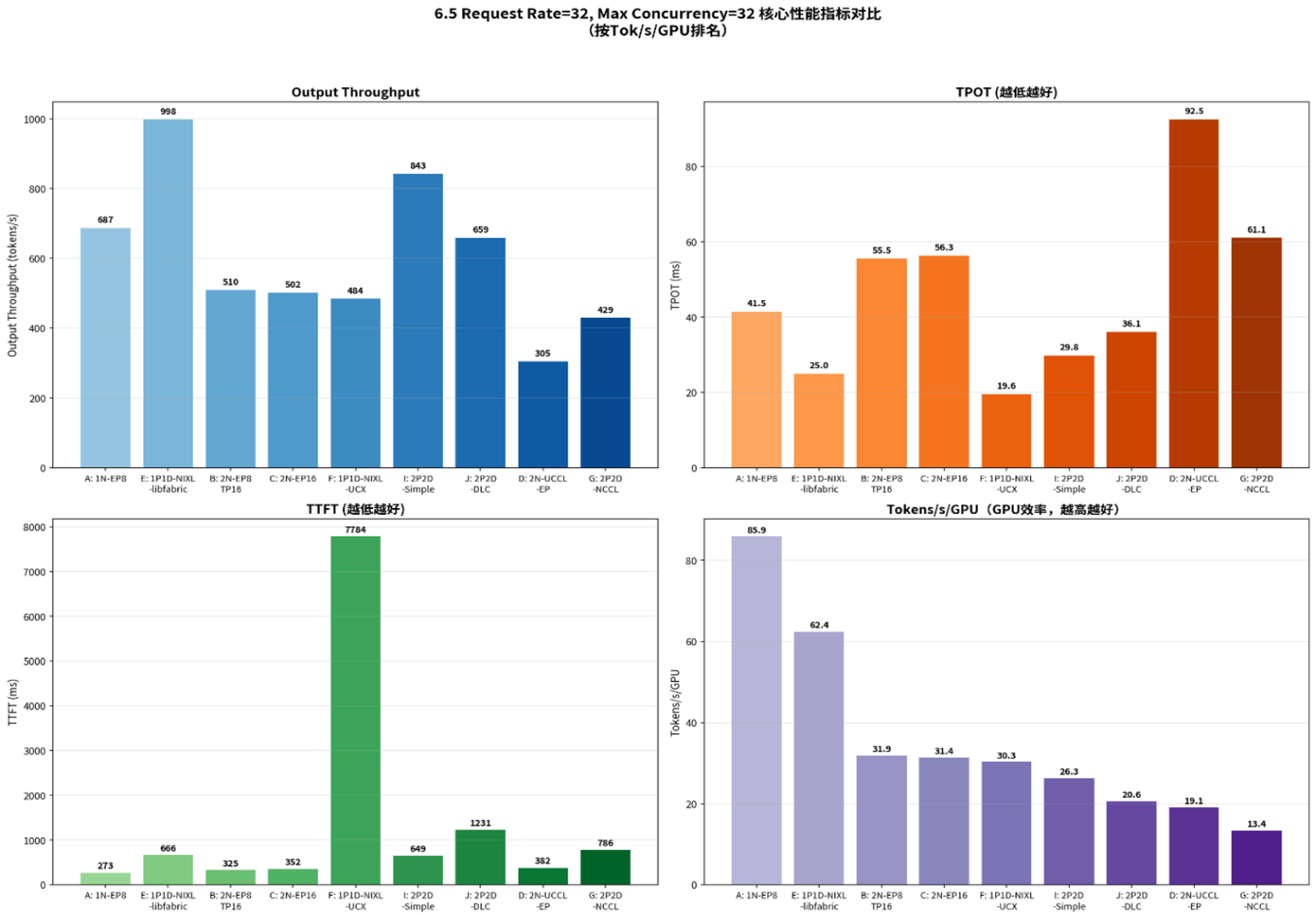
基于SGLang的大模型推理实践——从benchmark方法论到部署方案选型与调优
亚马逊AWS官方博客
·
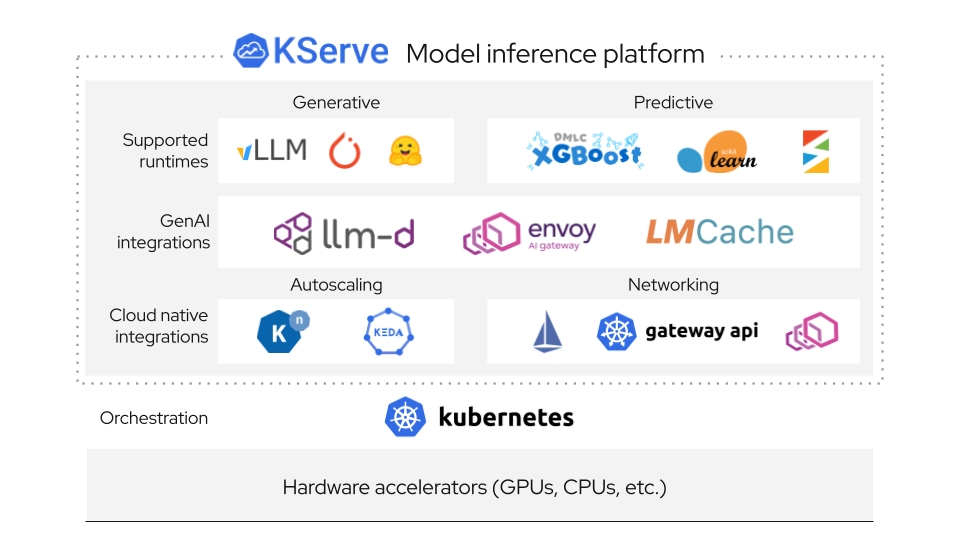
KServe 入门:部署第一个 vLLM 推理服务
探索云原生
·
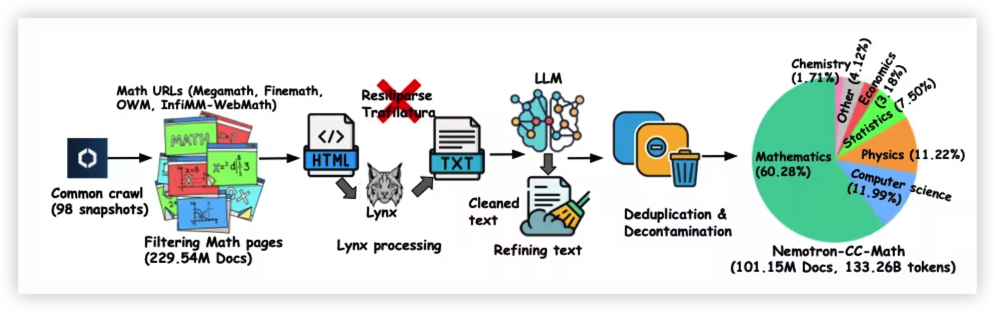


Thinking Machines推出的Inkling现已在AI Gateway上可用
Vercel News
·

CLaRa:通过连续潜在推理连接检索与生成
Apple Machine Learning Research
·


AI论文评审:自一致性提升语言模型中的链式思维推理
freeCodeCamp.org
·
