
面向电商直播场景的全模态大模型推理加速方案
内容提要
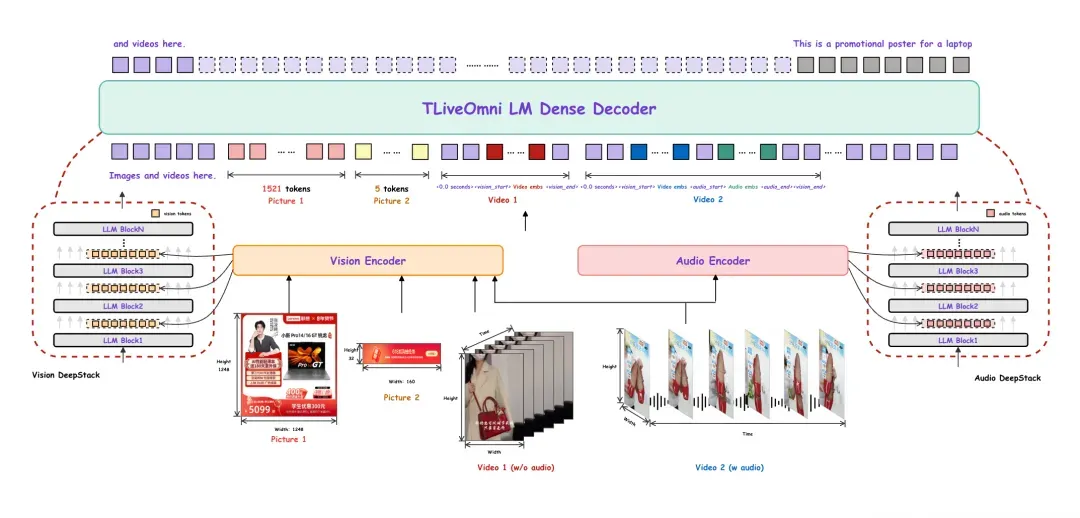
本文介绍了电商直播场景下的全模态理解大模型TLiveOmni在vLLM框架下的推理部署与量化优化。通过自定义插件和修复多模态Token排布,解决了vLLM对Omni模型支持不足的问题。采用SmoothQuant与GPTQ的复合量化方案,构建了5000条高质量数据的校准集,确保模型效果。最终在H20与RTX 4090上测试,推理加速达2.5至3.5倍,精度损失控制在1.5%以内。
关键要点
-
本文介绍了电商直播场景下的全模态理解大模型TLiveOmni在vLLM框架下的推理部署与量化优化。
-
通过自定义插件和修复多模态Token排布,解决了vLLM对Omni模型支持不足的问题。
-
采用SmoothQuant与GPTQ的复合量化方案,构建了5000条高质量数据的校准集以确保模型效果。
-
最终在H20与RTX 4090上测试,推理加速达2.5至3.5倍,精度损失控制在1.5%以内。
延伸解读
推理加速的实际意义
在电商直播场景中,推理速度直接影响用户体验。TLiveOmni模型通过量化优化实现了2.5至3.5倍的推理加速,这意味着在高并发情况下,用户能够更快地获得反馈,从而提升直播互动的流畅性和购买转化率。
量化方案的选择与影响
本文采用的SmoothQuant与GPTQ复合量化方案,旨在最大限度保留模型精度。量化不仅能显著降低显存占用,还能提高推理速度。选择合适的量化方案对于不同硬件平台的性能优化至关重要,尤其是在显存受限的环境中。
硬件选择的关键因素
在选择推理硬件时,H20与RTX 4090的性能差异显著。H20在处理长序列任务时表现优越,适合大规模生产场景,而RTX 4090则在显存受限的情况下表现良好。了解不同硬件的特性,有助于优化部署策略。
延伸问答
TLiveOmni模型的主要应用场景是什么?
TLiveOmni模型主要应用于电商直播场景,支持图像、文本、音频与视频的统一输入。
vLLM框架在推理部署中有哪些优势?
vLLM框架通过高效显存管理、极致吞吐与调度,显著提升了推理速度和系统吞吐量。
如何解决vLLM对Omni模型支持不足的问题?
通过自定义插件和修复多模态Token排布,解决了vLLM对Omni模型支持不足的问题。
TLiveOmni模型的推理加速效果如何?
TLiveOmni模型在推理加速方面达到了2.5至3.5倍,精度损失控制在1.5%以内。
SmoothQuant与GPTQ的复合量化方案有什么优势?
该方案通过优化激活值中的离群点和权重参数,最大程度保留模型精度,适用于大模型的工业级部署。
在不同硬件上,TLiveOmni模型的表现如何?
在H20上,TLiveOmni模型的推理性能显著优于RTX 4090,尤其在长序列任务中表现更佳。
