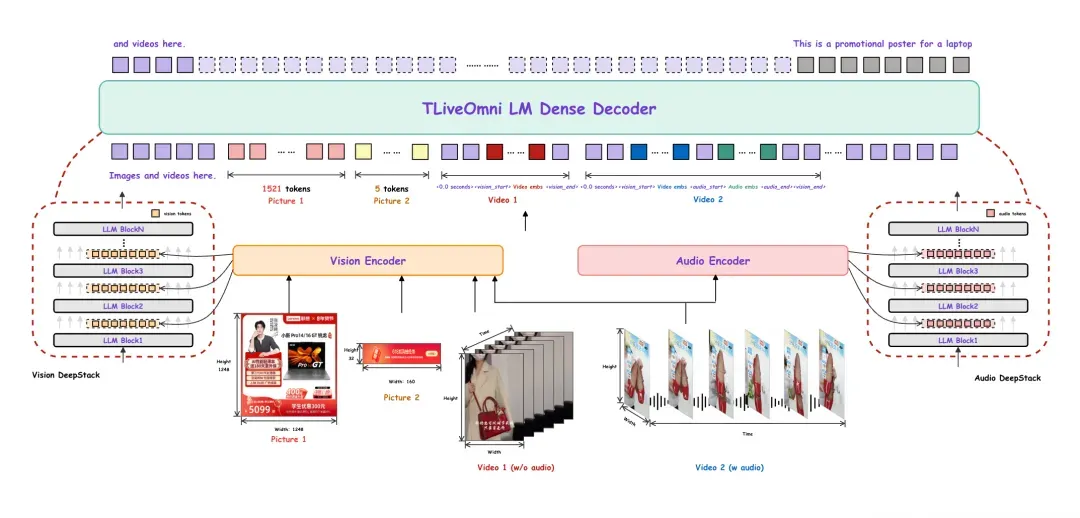
本文介绍了电商直播场景下的全模态理解大模型TLiveOmni在vLLM框架下的推理部署与量化优化。通过自定义插件和修复多模态Token排布,解决了vLLM对Omni模型支持不足的问题。采用SmoothQuant与GPTQ的复合量化方案,构建了5000条高质量数据的校准集,确保模型效果。最终在H20与RTX 4090上测试,推理加速达2.5至3.5倍,精度损失控制在1.5%以内。
完成下面两步后,将自动完成登录并继续当前操作。